YouTube Recommendation system 트릴로지 리뷰 - [3]
이전 포스팅 보기
YouTube Recommendation system 트릴로지 리뷰 - [1]
YouTube Recommendation system 트릴로지 리뷰 - [1]
본 포스팅은 2010, 2016, 2019에 발표한 유튜브의 추천시스템 자료를 리뷰한 것이다. 3부작이 끝이 아님에도 트릴로지라는 이름을 붙인 것은, 필자에게는 이 자료들이 매트릭스 3부작이나 반지의제왕 3부작 만큼이..
yamalab.tistory.com
https://yamalab.tistory.com/124
YouTube Recommendation system 트릴로지 리뷰 - [2]
YouTube Recommendation system 트릴로지 리뷰 - [1] 이번에 리뷰할 자료는 으로, 2016년에 발표된 것이다. 이 자료는 당시에 나오자 마자 읽어봤던 자..
yamalab.tistory.com
https://yamalab.tistory.com/125
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts 리뷰
본 포스팅은 YouTube recommendation system 트릴로지 리뷰(링크) 중, 스핀오프 영화 같은 개념이라고 생각하면 좋다(..). 본래 multi-task learning은 딥러닝 분야에서 많이 사용되던 방식인데, 저자가 아마도 유..
yamalab.tistory.com
이번에 리뷰할 자료는 <Recommending What Video to Watch Next: A Multitask Ranking System (2019)>으로, 가장 최근에 발표된 것이다. 회사에서 컨퍼런스 지원으로 이 발표 현장에 갈 뻔 했지만 아쉽게 무산되고 말았던 기억이 있다. 자료를 처음 받아보고 든 생각은, 유튜브 연구진이 굉장히 중국화 되었구나.. 라는 생각이었다. 개인적인 생각이지만 아마 10년 내로, 추천시스템이나 AI research 쪽에서 발표되는 연구자료의 저자는 대부분 중국인이 될 것 같다.
아무튼 이번 자료 역시 아주 재미난 자료이다. 워낙 성숙된 추천시스템이다보니 자료의 난이도가 조금씩 어려워지는 느낌은 있지만, 여전히 이해하기에 어렵지 않게 쓰여져 있다. 기존에는 추천의 메커니즘이나 candidate generation을 설명하는 쪽에 힘을 준 내용이었다면, 이번에는 랭킹 모델에 집중한 것으로 보인다.

1. Intro
이전 자료들에서 설명했듯이, 유튜브의 추천시스템은 candidate generation - ranking 두 가지의 단계로 나뉘는데, 이번에는 그중에서도 랭킹 모델에 집중하여 설명하고있다. 랭킹 모델에서 유튜브가 집중하여 풀고있는 두 가지 문제는 다음과 같다.
- 어떤 것을 최적화 할 것인지를 잘 조정해야 한다. 단순히 시청 시간이나 여부 뿐만 아니라, 영상의 공유나 선호 표시 역시 최적화의 대상이 되어야 한다.
- 유저는 단순히 영상이 높은 순위에 띄워져 있기 때문에 시청할 수도 있다. 따라서 feedback loop에 빠지지 않으려면 selection bias를 효과적으로 제거하는 방법이 필요하다.
두 가지 내용의 요약은 다음과 같다. objective를 잘 설정하자는 것, 그리고 추천의 bias를 잘 제거하자는 것이다. 이번에 이 문제들에 접근한 방식은 multitask neural network 라는 방법인데, 큰 그림은 아래와 같다.
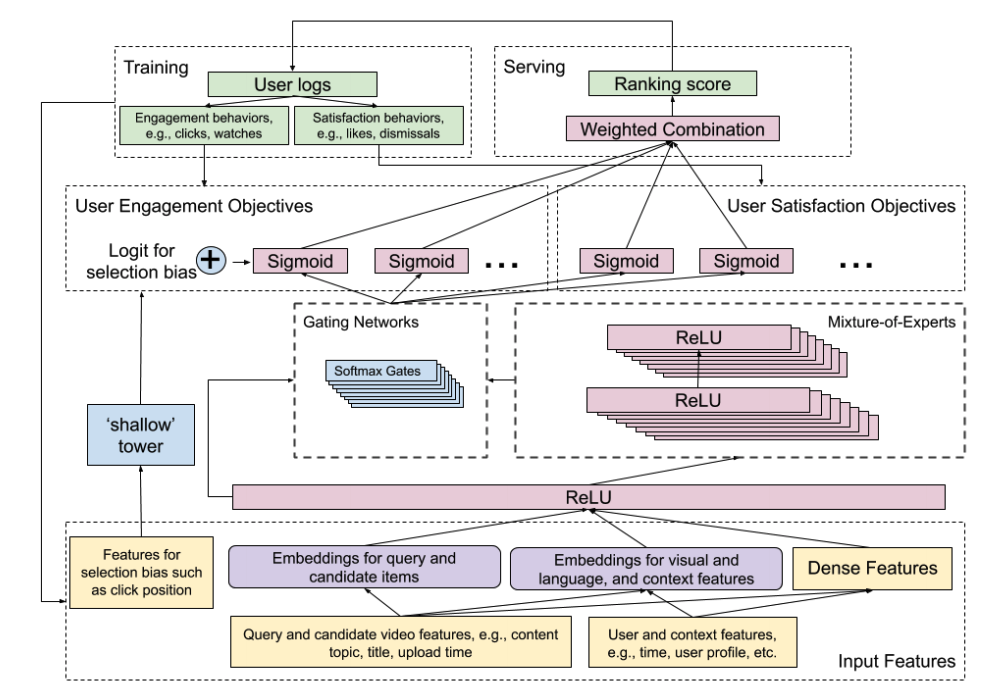
이 모델의 아키텍처는 Wide & Deep 모델(참고 링크)에 기반하여 Multi-gate Mixture-of-Experts(이하 MMoE. 관련 내용 참고 링크) 구조를 적용시킨 것이라고 한다. 이 구조를 적용한 이유는 objective를 분리하여 multitask learning을 구현하기 위한 것. 영상을 볼 때 다음에 "무슨 영상"을 클릭할 지도 중요한 objective 이지만, 그 영상을 "얼마나 시청할지", 혹은 "좋아할 지" 등의 objective를 분리하여 예측하기 위함이다. 2016년 논문에서 언급했듯이, "다음에 뭘 시청할지"만을 objective로 하여 예측한다면, 광고나 낚시성 영상에 어그로를 끌릴 확률이 높아지기 때문이다. 해당 논문에서는 weight를 주는 방식으로 이를 해결하였지만, 2019년에는 MMoE를 아예 도입해버린 것이다. 그리고 여기에 shallow tower라는 것을 도입하여 추천 순위에 따른 selection bias를 조금 더 제거한다고 한다.
우선 objective를 두 개의 그룹으로 분류했는데, 첫 번째는 engagement objective이다. 유저의 클릭, 영상에 대해 어느정도의 engagement를 가지고 있는지에 관한 것이다. 두번째는 satisfaction objective로 유저가 영상을 좋아하는지, rating을 어떻게 주었는지에 관한 것이다. 이해를 돕기 위해 쉽게 설명하자면, 첫번째 task는 클릭 예측, 두번째 task는 좋아요를 누를지를 예측하는 것이다.
이 모델은 크게 두 파트로 분리되는데, 첫 번째는 bias가 없는 user utility. 그리고 두 번째는 shallow tower를 통해 올라온 estimated propensity score이다. shallow tower의 input은 selection bias이며, wide & deep 모델에서 wide의 역할을 하게 된다. wide & deep 모델에서 wide의 역할은 resorting 되거나 임베딩 되지 않은 직접적인 피처를 활용할 수 있게 하는 것이다. 이는 selection bias를 아주 강하게 반영하겠다는 것이다.
2. Related Works
1) Industrial Recommendation Systems
이 단락에서는 추천시스템에서 중요한 요소들 몇 가지를 언급한다. 첫 번째는 (3편의 논문에 걸쳐 항상 이야기하지만) implicit 피드백은 추천시스템에서 가장 중요한 요소라는 것이다. explicit 피드백을 모으는 것은 현실적이지도 않고, 생각보다 별 쓸모도 없기 때문.
두 번째는 stage를 나누는 것이다. 대부분의 추천시스템이 candidate generatoin과 ranking 2단계로 분리되는데, 사용되는 방법이나 알고리즘 역시 어느정도 정형화 되어있는 것 같다. candidate generation에서는 association rule, co-occurrence 기반의 pool을 생성하거나 colaborative filtering을 사용하는 것이 가장 일반적. 그리고 ranking 단계는 learning-to-rank의 개념으로 설명할 수 있는데, 일반적으로 추천시스템은 point-wise, 검색시스템은 pair-wise나 list-wise 최적화를 사용한다. 추천시스템은 inference의 과정을 거쳐야 하기 때문에 속도 측면에서 각각의 '클릭'을 예측하는 point-wise가 효율적이고, 검색시스템은 역 인덱싱이 되어있기 때문에 성능 부담없이 pair-wise를 사용한다. 특히나 커머스 분야의 경우, 10개의 리스트 중 구매까지 일어나는 상품은 많아야 1~2개 이기 때문에 pair-wise를 사용하는것은 오히려 성능을 떨어뜨릴 확률이 있다. (이 내용은 논문에 언급된 내용은 아니다. 필자의 주관적 경험. learning-to-rank 참고 링크)
그리고 세 번째는 scalability이다. candidate generation 단계에서는 분산처리와 ETL 작업을 통해 효율적으로 item pool을 생성해내야 하고, 랭킹 단계에서는 효율적인 러닝 알고리즘(ALS, FTRL...)으로 방대한 데이터를 실시간으로 모델에 업데이트하는 프로세스가 필요하다. 그래서 모델의 퀄리티와 효율성 사이에서 절충하기 가장 좋은 메커니즘은 deep neural network + point-wise 랭킹모델이라고 한다.
2) Modeling Biases in Training Data
유저의 행동, 그리고 추천시스템 사이에서는 필연적으로 selection bias가 생긴다. 예를 들면 다음과 같은 상황이다. 유저가 클릭할 영상이 노출된 이유는 현재 시스템(모델)이 추천을 해주었기 때문이고, 유저는 이것을 누르며, 이 상황은 모델에 다시 학습된다. 이러한 상황을 feedback loop라고 하며, 대부분의 추천시스템이 해결해야 할 문제점이다.
이 문제에 대한 일반적인 대응법은 상위에 랭크되는 영상에 대해 모델 학습시에 가중치를 고의로 떨어뜨리는 것인데, relative work에 여러 가지 방법들을 설명해 놓았다. 그 중 이해하기 쉬운 하나의 예시는 다음과 같다. 모델의 input으로 rank position 정보를 입력하여 학습한 뒤, serving시에 position을 1로 고정하는 식의 트릭을 사용하는 것이다. 사실 이 부분은 구현자 각각의 시스템에 따라 조금씩 달라질 수 있는 것이고, 모로 가도 서울만 가면 랭킹정보를 고의로 눌러준다는 것 자체가 중요한 것이기 때문에 자세한 예시들을 쓰지는 않겠다. 만약 실제로 구현할 일이 있다면 예시 중에 하나를 골라서 응용하면 되겠다.
3. Problem Description
candidate generation, ranking 레벨로 문제를 define 하기 전에, 우선적으로 고려해야 하는 요소들은 Multimodal feature space와 Scalability 라고 정의하였다. Multimodal feature space란, candidate 레벨에서 user utility를 만들어 낼 때 다음과 같은 요소들을 multimodal 하게 사용한다는 것이다. video content, 썸네일, 소리, 제목, 유저 demo 등의 요소이다.
candidate generation을 조금 살펴보면, 2010년과 2016년 논문의 내용과 거의 유사하다. 물론 내부적으로는 엄청난 발전이 있었겠지만 말이다. 기본적인 generation은 쿼리에 대한 결과를 반환하는 것으로, user history에 기반한 정보를 query로 하여 몇 가지 방법의 후보군들(시나리오들)을 반환한다. 그 방법으로는 같은 세션 내 동시 시청한 비디오를 추천하는 association rule 기반 방식, 영상의 topic을 추출하여 매칭하는 방식 등이 있다고 한다. 여기에서 후보군을 생성하는 시나리오는 몇 개인지, A/B 테스트는 얼마나 해봤는지 등을 써줬으면 더 좋았을텐데 그 점은 약간 아쉽다.
4. Model Architecture
앞서 설명한 것처럼, 랭킹 모델은 MMoE를 기반으로 하며 Objective를 크게 두 가지로 분리했다. 첫 번째는 engagement에 관한 것이고 유저의 클릭(binary classification task)과 시청 시간(regression task)으로 나뉘어진다. 두 번째는 satisfaction에 관한 것으로, 좋아요(binary classification task)와 rating(regression task)같은 문제로 정의할 수 있다. 그리고 모델은 최종적으로 이러한 multiple objectives를 combined score로 사용한다.

위 그림의 오른쪽은 MMoE에 대한 그림인데, MMoE를 도입한 이유는 다음과 같다. 일반적인 multi-task learning 문제에서는 shared bottom 네트워크 모델을 사용했었는데, 만약 task간의 연관성이 낮다면 shared bottom 네트워크는 성능이 시원찮을 가능성이 높기 때문이다. 조금 더 자세한 설명은 포스팅 하단의 논문을 참고하자.
그리고 아래의 그림은 Selection bias에 대한 것인데, 포지션 정보(추천 랭킹 순위)를 feature로 활용한 것과 다른 피처(예를 들면 device id)를 linear combination 하여 selection bias로 만들어냈다는 것을 알 수 있다. 이 피처는 serving 시에는 missing value로 통과시켜, 이에 따라 높은 랭킹에 페널티를 주는 방식을 선택한다.

또한 논문에서는 selective bias에 대한 간략한 설명을 포함하고 있는데, 위에서 서술한 내용과 크게 다른 점은 없고, 한가지 내용을 추가하였다. 그 내용은 모든 impression 데이터를 position 피처로 활용하면서, 모델이 너무 wide part에 의존하지 않게 10%의 dropout을 적용했다는 것이다.
5. Experiment Results
multiple objectives를 combined score로 seving한다고 언급하였지만, 오프라인 테스트 단계에서는 task별 AUC, squared error를 주로 관찰한다고 한다. 그리고 A/B 테스트와 오프라인 테스트의 결과를 종합하여 하이퍼 파라미터를 튜닝한다고 한다.
모델 자체의 성능에 관한 리포팅은 MMoE를 적용 한 것과 안한 것의 성능 대조, Expert utilization에 대한 시각화(Gating network distribution), wide feature(position bias)와 관련된 CTR 대조를 설명해 두었다. 아래의 그림들은 이를 차례대로 나타낸 것이다.


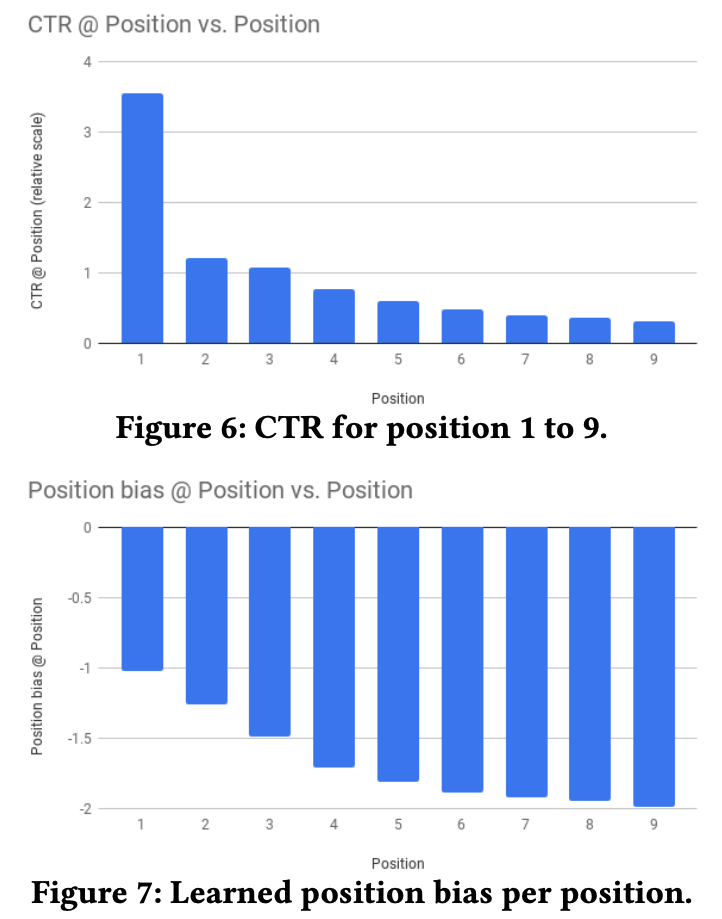
<관련하여 읽어보면 좋은 논문 리스트>
Unbiased Learning to Rank - https://ciir-publications.cs.umass.edu/getpdf.php?id=1297
Wide and Deep 모델 - https://arxiv.org/abs/1606.07792