본 포스팅은 차원 축소 기법에 대해 조금 더 자세히 정리하는 차원의 글이다. 기존에도 SVD(링크), t-SNE(링크)에 대해 언급한 적은 있지만 intuitive한 정도로만 이해하고 넘어갔었다. 차원 축소는 가장 기본적인 방법인 행렬 분해를 이용하는 방법, 그리고 확률적 차이를 이용하는 방법, Neural Network를 활용하는 방법 등이 있다. 이번에는 행렬을 이용하는 방법과 확률적 차이를 이용하는 방법에 대해서 간단하게 정리하고자 한다.
1. 선행 개념
1) Eigen-decomposition
PCA와 SVD를 이해하기 전에 선행 지식이 되는 개념이다. 고유 분해는 정방 행렬 A가 있을 때, 다음과 같은 성질을 만족하는 영벡터가 아닌 벡터 v와 실수 𝜆를 찾아내는 것이다. v는 eigen vector, 그리고 𝜆는 eigen value라고 한다.

eigen vector는 크기가 가변적이지만 direction은 바뀌지 않는 선형적 특성을 가지고 있는 벡터이다. 때문에 벡터에 어떠한 상수 c를 곱하던, 그것 역시 eigen vector라고 할 수 있다. 그래서 일반적으로 eigen vector를 구할때는, v의 크기만큼 normalization을 적용한다.
v와 𝜆를 구하는 과정은 다음과 같다.
- (A-𝜆I)v = 0 이라는 식으로 정리
- 위 식은 (A-𝜆I)가 역행렬이 없다는 것을 의미한다. 따라서 (A-𝜆I)를 ([[a,b], [c,d]]) 라고 할 때, ad-bc=0 이라는 역행렬의 성질을 이용하여 v와 𝜆를 계산할 수 있게 된다. (이에 대한 자세한 전개는 생략한다)
당연하게도 v와 𝜆 값은 유일한 값이 아니라, 여러 개가 생성될 수 있다.
2) Singular Value Decomposition
특잇값 분해라고 불리는 이 개념은, 정방행렬이 아닌 행렬에 대해 총 3개의 행렬의 곱으로 나타내는 방법이다.

특잇값 분해는 다음과 같은 3가지 조건을 만족한다. SVD에서는 아래의 성질들, 그리고 Eigen-decomposition의 성질을 이용하여 각 3개의 행렬을 구할 수 있다.

- Σ 행렬은 positive diagonal component를 가지고 있는 행렬이며, m x n의 크기를 가지고 있다.
- U 행렬은 모든 열 벡터가 unit vector이면서 orthogonal한 정방 행렬이다.
- V 행렬은 모든 열 벡터가 unit vector이면서 orthogonal한 정방 행렬이다.
만약 User X Movie Rating Matrix에 대해 SVD를 수행했다면, U행렬과 V행렬을 latent factor로써 활용할 수 있고, Σ의 에서 대각 행렬의 요소를 n개만 선택한다면 User(혹은 Movie)를 표현하는 Vector dimension을 n개로 축소할 수 있다. 이를 잠재 의미 분석(LSA)라고 부르기도 한다.
3) Optimization
본 포스팅에서 소개할 차원 축소 방법들에 사용되는 Optimization 개념들만 간단하게 짚고 넘어가자. 우선 기본적으로 알아야 하는 것은 당연히 Gradient Descent이다(이하 GD). GD는 어떤 Objective function이 있을 때, 임의의 파라미터 Theta를 추정해나가는 과정으로, iterative하게 optimization을 수행한다. 아래의 식으로 일반화가 가능하며, Cost를 point-wise 하게(혹은 mini-batch로) 정의하면 Stochastic Gradient라고 불린다.

이 외에도 다양한 Optimizer들이 개발되었고, 이에 대한 조금 더 자세한 정보는 링크를 참고하자. SVD는 원래의 입력 행렬의 값들이 모두 존재한다면 Gradient Descent를 사용하지 않고 위에서 언급한 방식대로 행렬들을 찾아낼 수 있지만, 대부분의 값이 Sparse vector인 추천시스템 같은 상황에서는 Gradient Descent 방식으로 SVD의 분해 행렬들을 추정하기도 한다. 이를 추천시스템의 Matrix Factorization의 관점에서 해석하여 ALS같은 방식을 사용하는 활용 방법도 있다. ALS에 대해서는 다음 포스팅에서 설명하도록 하겠다.
다음으로 GD와 함께 알아두어야 하는 개념은 라그랑즈 승수법(Lagrange Multiplier)이다. 머신 러닝 모델을 파헤치다 보면 심심치않게 등장하는 개념인데, 내용은 아주 간단하다. 최적화 문제를 풀 때, 문제에 특정 조건이 있다면 그것을 하나의 식으로 함께 편입시켜 최적화를 진행하는 방법이다. 아래의 식과 같은 문제 상황이 있다고 가정할 때, f(x)는 원래 문제에서의 목표 함수, 그리고 g(x)는 문제에서의 특정 조건인 constrained condition이 된다.
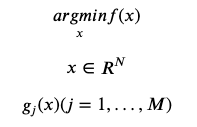
라그랑즈 승수법은 아래 식처럼 문제를 일원화한 뒤, 각각의 요소에 대해 편미분값이 0이 되는 지점을 조합하여 최적화를 수행하는 과정이다. 하지만 문제가 등식이 아니라 부등식이라면, 조금 더 문제가 복잡해진다. 이 때 고려해야 하는 개념이 KKT(Karush-Kuhn-Tucker)인데, 주제를 많이 벗어나므로 이 포스팅에서 다루지는 않겠다.
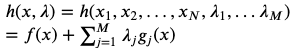

2. PCA
PCA는 가장 잘 알려진 Feature reduction, 혹은 Feature extraction 방법이다. 알고리즘의 목적은 데이터의 분산을 최소화 하면서 데이터를 투영(Projection)할 수 있는 새로운 축을 찾아내는 것이다.
1) Feature Extraction
p차원의 피처를 가진 n개의 데이터를 행렬 X(p x n)이라고 표현한다면, 이를 축소하여 k x n 의 새로운 행렬을 만들어내는 과정을 Feature extraction 이라고 한다. 아래와 같은 식이 있을 때, Z는 축소된 행렬을 의미하고, A^T는 데이터를 사영할 축을 의미하며 X는 원래의 행렬이다.
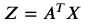
PCA의 목적을 다시 한 번 상기해보면, 데이터를 새로운 축에 사영시켰을 때 데이터의 분산이 최대가 되어야 하는 축을 찾는 것이다. 그리고 사영 후에 분산이 크려면, 그 축은 반드시 eigen vector가 되어야 한다. 이 명제를 증명하는 과정에서 필요한 것이 라그랑즈 승수법이고, 증명 과정을 따라가다 보면 원래의 행렬 X에 대한 공분산 행렬을 Σ이라 했을 때 Σ에 대한 고유 벡터와 고유값을 구하는 것이 PCA의 주 과정이라는 것을 알게 된다. 이에 대한 증명 과정은 링크를 참고하자.
2) Summary
정리하면, 원 행렬 X가 있을 때, Cov(A) = Σ 이고, Σ의 eigen vector와 eigen value를 구하는 것이 PCA의 과정이다. 이를 통해 ΣV = V⋀ (⋀ = eigen value를 대각성분으로 하는 대각 행렬)라는 식을 도출할 수 있고, VT와 X를 내적한 것이 최종적으로 축소된 행렬 X`가 된다.
또 하나 알아두면 좋은 것은 바로 SVD와 PCA의 관계다. PCA는 원 행렬의 Cov Matrix(정방 행렬)에 대한 eigen decomposition을 한 것이고, SVD는 M x N matrix에 대한 singular decomposition을 한 것이다. 식으로 살펴보면 PCA는 A^T A = V ⋀ V^T 이며 SVD는 A=UΣV^T 이다. 그리고 이 두 식에 몇 번의 전개를 거치면 PCA의 ⋀과 SVD의 Σ가 동일한 역할을 하고 있음을 알 수 있다. 즉, SVD의 Σ 행렬은 PCA의 eigen value의 의미와 똑같다는 것이다. 이러한 성질을 이용하면 SVD를 조금 더 잘 활용할 수 있게 된다.
참고 자료들
- https://datascienceschool.net/view-notebook/04358acdcf3347fc989c4cfc0ef6121c/
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/06/pcasvdlsa/
'Programming & Machine Learning > 풀어쓰는 머신러닝' 카테고리의 다른 글
| 시계열 분석 이론의 기초 - 2 (0) | 2020.07.24 |
|---|---|
| 행렬 분해와 차원 축소의 기법들 - [2] (0) | 2020.06.04 |
| 시계열 분석 이론의 기초 (3) | 2019.01.12 |
| GAN 모델의 이해와 구현 (3) | 2018.08.17 |
| Softmax Classifier의 이해 & Python으로 구현하기 (0) | 2018.07.08 |