이번에는 GNN(Graph Neural Network) 관련 임베딩 시스템을 우버잇츠에서는 어떻게 활용했는지에 관한 내용이다. 지난 포스팅들보다는 다소 기술적인 내용이 포함되어 있어 조금 더 흥미롭다. 요번 포스팅 역시 원문에 주관적 해석을 약간 덧붙인 번역문에 가까우니, 영어가 자신있는 분은 원문을 읽는 것을 권장한다.
https://eng.uber.com/uber-eats-graph-learning/
1. Graph learning in a nutshell
UberEats의 추천 모델을 제대로 이해하려면, Graph Learning의 동작 방식을 이해할 필요가 있다.
대부분의 ML Task는 그래프 구조의 노드를 표현하는 학습방법을 사용할 수 있다. 노드의 표현이라는 것은 encode properties를 그래프의 구조에서 가져왔다는 것이다. 그래서 유저, 레스토랑, 메뉴 등을 그래프 기반으로 벡터 표현한 뒤, 그래프에서 가깝게 위치할수록 vector similarity가 높아지는 개념으로 전체적인 아키텍처를 디자인할 수 있다. 우버잇츠에서는 이러한 인코딩 함수를 정의하기 위해 GNN-based 모델을 채택하였다.
GNN의 기본적인 아이디어는 아래의 그림처럼 인접한 노드의 reperesentation을 recursive하게 특정 depth까지 aggregation 하는 것으로부터 시작한다.

만약 A의 representation을 구하는 경우, recursive depth를 2로 제한한다고 가정해보자. 그러면 위의 그림처럼 breadth-first search로 A와 인접한 B,C,D 노드부터 aggregating을 수행한다. 이러한 방식으로 임베딩을 하는 주된 이점은, 노드 A의 속성과 그 인접 노드에 대한 정보를 모두 사용하여 아래 그림과 같이, 노드 A와 연결되는 모든 노드에 대한 정보를 수집한다는 것이다.

모든 노드에 대한 representation을 완료했다면, link prediction과 같은 ML Task 수행이 가능해진다(인접한 노드의 link probability를 최대화하고, 연결되지 않은 노드를 minimize 하는 방식으로 -> 아래에 다시 언급하는 loss 함수에서 positive와 negative의 개념이다).
GNN을 통한 그래프 임베딩 표현의 장점은, 그래프 사이즈에 관계 없이 그리 많지 않은 양의 파라미터만을 사용한다는 것이다. 그리고 이는 곧 large scale로의 쉬운 확장을 의미하기 때문에 매우 큰 장점이라고 할 수 있다. 또한 새로 추가된 노드에 대해서도 벡터 표현이 가능하다.
2. Graph learning for dish and restaurant recommendation at Uber
UberEats의 추천 시스템 역시, Candidate Generation 단계와 Personalized Ranker 두 단계로 나뉘어 디자인되었다. Candidate generation component 에서는 후보군 위주의 확장 작업을 한다. 이를테면, 최근 조회한 몇 개의 레스토랑을 가지고 similar 레스토랑을 추출하여 전체 후보군 자체를 확장하는 등의 작업을 의미한다. 추천 결과로 나가는 레스토랑이나 메뉴에 대한 사전 필터링이 필요하기 때문에 후보군 확장은 필수적인 단계인데, 좋은 추천을 위해 pool을 넓힌다 정도로만 이해하면 될 것 같다.
Personalized Ranker는 넓혀진 pool 안에서, 유저의 선호도에 따라 추천 대상을 선택하는 것이다. 이러한 서비스 유형의 Personalized Ranker가 가장 중요하게 고려하는 것은 사용자의 Context 정보인데, Food-tech 분야에서는 요일, 시간, 현재 위치 등이 core feature인 것으로 보인다(오전에 치킨을 시키지는 않을 것이고, 일요일은 짜파게티 요리사이므로).
GNN 모델을 여기에 써먹으려면, bipartite graph를 두 개 생성해야 한다. 하나는 유저와 메뉴를 포함하는 그래프 정보인데, edge의 weight를 주문 횟수로 사용하는 그래프를 생성한다. 두번째는 유저와 레스토랑을 포함하는 그래프 정보로, edge에 유저-레스토랑간의 주문 횟수를 저장한다.
이를 위해 GraphSAGE 알고리즘을 사용했으며, 1~2 depth 인접 노드를 모두 사용하면 scalability 문제가 생길 수 있기 때문에 특정한 샘플링 기법을 사용했다고 한다. (Negative Sampling 개념인 듯 하다) 그리고 기본적인 GNN 모델에서 더 추가된 점은, 인접 노드의 type(user, dish, restaurant...)이 서로 다를 확률이 높기 때문에 additional projection layer를 추가했다고 한다. 그래서 이 layer를 거치면 노드 타입에 상관없이 같은 크기의 벡터로 표현된다. 유저, 메뉴, 레스토랑 등은 각기 다른 피쳐와 형태를 가지고 있기 때문에 이를 같은 vector space에 놓을 수 있는 projection 레이어를 하나 더 둔 것이다.
또 하나 더 고려한 것은, edge를 binary한 변수로 두지 않고, 주문 횟수를 score로 edge를 활용했다는 것이다. 그래서 모델 학습시에 binary loss 를 사용하지 않고, 아래와 같은 hinge loss를 사용했다고 한다.

만약 유저 u가 적어도 한 번 이상 메뉴 v를 주문했다면, weighted edge가 그래프에 존재하게 된다. 이 edge score를 predict 문제에서, u-v 쌍이 무작위로 선택된 u-n 쌍(유저가 주문해보지 않은 메뉴)보다 높으려면 weighted score가 더 좋기 때문이다. 그러나 이러한 방식으로 loss를 정의해도, score의 고저가 심한 경우가 있기 때문에 (한 번 주문한 경우와 100번 주문한 경우의 edge들) low-rank positives의 개념을 loss에 추가한다.
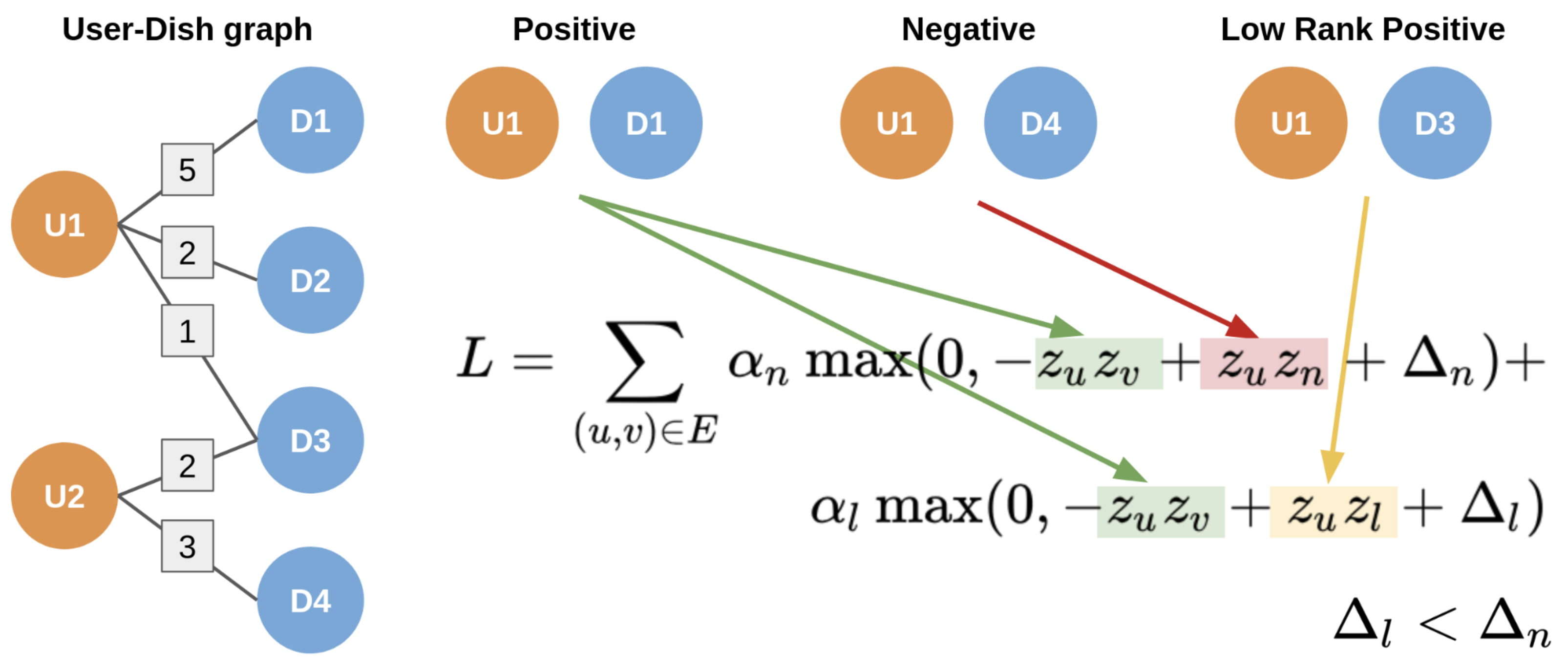
위의 그림은 low-rank positive를 어떻게 활용하는지를 설명하는 것이다. positive edge를 <u, v> 라고 할 때, low-rank positive edge를 <u, l> 이라고 한다. 노드 u는 동일하지만, v와 l은 다르며 edge의 score는 l이 더 낮다. 이같은 수식을 디자인 한 이유는, higher weight edge를 가진 노드를 확실하게 부스팅해주기 위한 것이다. 만약 연결되지 않은 (U1, D4)만을 Negative 라고 샘플링하여 loss를 계산하는 부분만을 활용하게 되면, (U1, D1) <-> (U1, D3)간의 선호도 차이 같은 것을 반영할 수 없기 때문이다. 그리고 단순히 구매하지 않았다고 Negative Sample로 판단하는 것도 한계가 있는 부분이기 때문인 것 같다.
위와 같은 노드 벡터 학습 과정을 통해 representation을 얻어냈다면, 이제 벡터 사이의 거리를 사용하여 노드 간의 유사성을 approximately 하게 사용할 수 있다. 대표적인 예로, 벡터의 cosine similarity를 이용하여 연관성이 높은 레스토랑을 추천하는 등으로 사용하는 예시가 있을 것이다.
3. Data and training pipeline
GNN을 서비스로 활용하기 위한 데이터 파이프라인을 살펴보자. 아래 그림과 같은데, 특별할 만 한 것은 없지만 두 가지 프레임워크가 눈에 띈다. 하나는 Cypher 라는 그래프 데이터를 질의하는 쿼리 언어 이고, 나머지 하나는 NetworkX 라는 그래프 데이터 자료구조 라이브러리이다.

전체 파이프라인에서 첫 번째 단계는 Apache Hive 테이블에 parquet 형태로 데이터들을 저장하는 것이다. 데이터는 두 벌의 데이터로, 하나는 노드 정보를 담고 있고 나머지 하나는 엣지 정보를 담고 있는 파일이다. 데이터는 data 단위로 versioning 되어있고, 이는 과거 정보도 저장하기 위함이다.
두 번째 단계에서는 가장 최신의 그래프 데이터만 Cypher의 포맷으로 HDFS에 저장한다. 만약 Training task가 수행된다면, 현재 단위로 한 번(product), 그리고 과거 단위로 한 번(오프라인 테스트용) 실행한다고 한다.
세 번째 단계는 Apache Spark의 Cypher Query로 각 도시마다 partitioned 된 그래프 데이터를 전처리하는 것이다.
그리고 마지막 네 번째 단계에서는 도시 단위로 전처리된 그래프 데이터를 networkx 포맷으로 변환하여 ML 학습에 용이한 형태로 처리하는 작업을 수행한다. 이 모든 단계를 거쳐 생성된 임베딩 데이터는 ML에 활용하기 위한 형태로 lookup table에 저장된다.
4. 기타
UberEats 에서는 GNN 모델 도입을 통해, 추천시스템의 MAP, NDCG 등이 향상되었다고 하고, 개인화 랭킹모델의 AUC도 향상되었다고 한다(분석 결과 임베딩 피처가 랭킹모델에서 가장 높은 중요도를 가진다고 한다). 당연히 성능이 좋아진 내용들을 서술했을 것이니 이 부분은 생략하도록 하겠다. 임베딩 자체의 성능을 측정함에 있어서 Parallax: Visualizing and Understanding the Semantics of Embedding Spaces via Algebraic Formulae 방법을 사용했다고 하는데, 이 부분은 유용한 것 같으니 한 번 읽어볼 필요가 있겠다.



