지난 포스팅에서는 Learning to Rank에 대한 intuitive한 내용들을 다루었다. 이에 대한 내용을 다시 한 번 상기하자면, 검색과 추천같은 '랭킹'이 중요한 서비스의 경우, 아이템의 순위를 어떻게 정하느냐가 서비스의 품질을 결정한다고 할 수 있다. 그리고 이를 평가하기 위한 가장 정교한 방법은 list-wise 방법으로, nDCG를 대표적인 예로 들 수 있다.
그렇다면 이제 pair-wise ~ list-wise 정렬을 잘 하는 방법, 즉 "순서 정보를 이용하여 모델을 학습하는 방법"에 대해 알아보자. 이를 가장 잘 대표하는 방식이 바로 RankNet 계열의 알고리즘이다. 이는 Microsoft Research에서 연구한 내용으로, 순서 정보를 이용하여 뉴럴넷을 학습하는 랭킹 알고리즘의 기초이다. 현재는 훨씬 더 발전된 알고리즘과 연구들이 나와있지만, '수학의 정석'을 들여다보는 기분으로 이 방법들을 알아보도록 하자. 오늘 다룰 알고리즘은 RankNet이다.
RankNet은 마소 연구팀의 웹 검색 결과 개선을 위한 프로젝트의 초기 결과물이었다. 알고리즘은 (현재의 관점에서는) 간단하다. 검색어 쌍 [A, B]가 있다고 할 때, P(AB)가 0.5 이상이면 A가 B보다 높은 검색 순위, 이하이면 B가 A보다 높은 검색 순위라는 Logistic Regression을 output node로 한 뉴럴 네트워크를 구성하는 것이다. 구조도를 간단히 그려보면 아래와 같다.

알고리즘을 설명하는 논문(링크)을 살펴보면, 이 네트워크가 동작하는 원리와 Gradient Descent로 W를 업데이트하는 방법, 그리고 pair로 맺어진 데이터를 모델로 학습할 때의 Combining probability에 대해 설명하고 있다. 이에 대한 학문적 논의를 생략하고 cost function만을 살펴보면, 현재 우리가 사용하고 있는 평범한 cross entropy cost function을 사용한다는 것으로 요약할 수 있다.
즉, RankNet은 아래와 같은 확률을 활용하는 것이며,

이는 다시 정의하면 output node의 확률을 다음과 같이 정의한다고 할 수 있다.

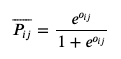
그리고 최종적인 cost function은 다음과 같이 정의할 수 있다.
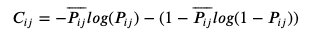
위의 정의대로 학습한 모델의 성능은 nDCG로 최종 평가하게 된다. 그래서 RankNet을 간단히 구현해 보았다. 코드는 아래와 같고, 상황에 맞게 pair를 생성하는 코드와 nDCG를 평가하는 코드 등을 수정하면 될 것 같다. 실제로 RankNet 계열의 알고리즘을 사용할 때는, 네트워크를 변형하여 구성하거나 파라미터 튜닝을 하는 것 보다도 pair를 생성하고 y를 잘 매칭해주는 작업이 훨씬 중요해 보인다.
import numpy as np
import keras
from keras import backend
from keras.layers import Activation, Dense, Input, Subtract
from keras.models import Model, Sequential
def base_network(input_dim):
model = Sequential()
model.add(Dense(input_dim, input_shape=(input_dim,), activation='relu'))
model.add(Dense(100, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(1))
return model
input_dim = 200
n = 100
# define input
pre_pair_input = Input(shape=(input_dim,))
post_pair_input = Input(shape=(input_dim,))
# get pair network
base_model = base_network(input_dim=input_dim)
rel_score = base_model(pre_pair_input)
irr_score = base_model(post_pair_input)
# subtract each score
diff = Subtract()([rel_score, irr_score])
# activate sigmoid function
prob = Activation("sigmoid")(diff)
# build
model = Model(inputs=[pre_pair_input, post_pair_input], outputs=prob)
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=['accuracy'])
# data : a is always higher than b
doc_a_feature = np.random.uniform(size=(n, input_dim)) + 1
doc_b_feature = np.random.uniform(size=(n, input_dim))
y = np.ones((n, 1))
# train
history = model.fit([doc_a_feature, doc_b_feature], y, epochs=10, batch_size=100, validation_split=0.2)상세 코드 : 링크
yoonkt200/ml-theory-python
Contribute to yoonkt200/ml-theory-python development by creating an account on GitHub.
github.com
+ nDCG 평가 코드 : 링크
참고 자료 :
https://icml.cc/2015/wp-content/uploads/2015/06/icml_ranking.pdf
https://www.microsoft.com/en-us/research/blog/ranknet-a-ranking-retrospective/
'Recommender System > 추천 시스템' 카테고리의 다른 글
| [Recommender System] - 임베딩 벡터의 Nearest Neighbor를 찾는 과정 (0) | 2020.12.03 |
|---|---|
| [Recommender System] - Factorization Machine (From Scratch with Python) (0) | 2020.04.17 |
| Learning to Rank와 nDCG (0) | 2019.08.13 |
| [Recommender System] - 개인화 추천 시스템의 최신 동향 (7) | 2019.06.17 |
| [Recommender System] - Autoencoder를 이용한 차원 축소 기법 (2) | 2019.05.20 |



