본 포스팅은 2020년에 발표한 MultiSAGE 알고리즘(MultiSage: Empowering GCN with Contextualized Multi-Embeddings on Web-Scale Multipartite Networks)의 내용을 GCN의 대략적인 히스토리와 함께 엮어낸 것이다. 기술의 주제 자체가 추천시스템인 만큼, 추천시스템과 관련된 내용만을 다루고 있으며 꽤나 많은 부분의 내용을 포스팅 최 하단의 링크들을 참고하여 작성하였다.
1. GCN (Graph Convolutional Neural network)의 개요
1) GCN의 특징
Graph Neural Network는 서로간의 연결관계를 갖고 있는 데이터를 Computer Science 영역의 그래프 표현 방법으로 잘 나타내기 위해 발전되어온 표현법이라고 할 수 있다. 크게 두 가지의 접근법이 있는데, 하나는 Spectral한 표현방법으로 나타내는 것이고 나머지 하나는 Spatial하게 그래프를 표현하는 것이다. Spectral 표현방식으로 가장 대표적인 것은 Laplacian Matrix로 그래프를 표현하는 것이다. 그리고 여기에 eigen decomposition을 수행하면 localized한 피쳐를 활용 가능함과 동시에 마치 Marix Factorization과 같은 효과를 기대할 수 있다. 다만 이 방법은 Transductive한 학습만이 가능하다는 단점과 동시에 MF 알고리즘이 가지고 있는 대부분의 단점(exponential한 연산량 증가 등)을 동시에 안고있다는 문제가 있다. 그래서 대부분의 GNN 관련 연구는 Spatial한 접근법으로 문제를 해결하는 쪽으로 진행되고 있다.

GNN은 보통 GCN으로 더 많이 표현되는데, 그래프는 인접 노드와의 관계가 중요한 데이터 구조이기 때문에 Convolutional한 접근법이 필요하기 때문이다. 그러나 일반적인 Neural Network에서의 Convolution의 개념과 Graph 구조에서의 Convolution의 개념은 약간 다르다. 기본적으로 convolutional한 연산을 수행한다는 점에서는 같기 때문에 convolutional process라는 점은 같지만, Graph 구조에서는 aggregation을 반드시 수행해야 한다. Graph 자료구조는 Topological한 특징을 갖는 반면, 이미지나 일반적인 CNN 네트워크의 대상이 되는 자료구조는 픽셀이나 벡터처럼 상대적 표현이 아닌 절대적 표현을 갖는다. 따라서 그래프 자료구조는 aggregation을 수행하는데, 그 중에서도 concat은 여전히 topological 특징을 반영하게 되기 때문에 concat aggregation은 사용하지 않는다.

그렇다면 이 aggregation이라는 것을 잘 하는게 그래프 표현을 잘 하는 것에서의 핵심이 될 것이다. 이것을 잘 하기 위해 고안된 몇 가지 아이디어는 다음과 같다.
- Message Passing : GCN에서의 FC layer는 Message Passing으로 이루어진다고 할 수 있다. aggregation은 인접 노드의 정보를 활용하여 자신(노드)을 표현하는 것인데, 이 과정에서 인접 노드와 정보를 주고받는 과정을 Message Passing이라고 한다.
- Residual Connection : Message Passing 만으로는 자신을 표현하기에 부족하다. 그래서 자기 자신의 정보를 표현하는 것도 당연히 필요하기 때문에, Message Passing으로 전달된 정보와 함께 자기 자신의 정보를 보존하는 Residual Connection과 함께 사용한다.
- Link Normalization : 이웃이 많은 노드는 당연히 정보량이 많아지기 때문에, 자신과 연결된 노드의 수로 나누는 등의 Link Normalization이 필요하다.
2) GraphSAGE (Graph + SAmple and AGgregate)
그래프 자료구조는 laplacian matrix (혹은 adjacency matrix)를 사용하게 되는 구조이다. 하지만 이러한 자료구조는 데이터의 크기가 커질수록 연산량과 메모리 사용량이 기하급수적으로 증가하기 때문에, mini-batch와 같은 형태로 샘플링을 해줄 필요가 생긴다. 즉, 이러한 Spatial 관점에서 접근한 것이 바로 GraphSAGE이다.
GraphSAGE의 핵심은 샘플링 기법을 새롭게 적용하고, aggregation에서 흔히 사용하던 degree and norm 방식 대신 새로운 가중치 적용 방법에 대해 연구한 것이다. 그래프 구조에서 다음 노드에 message passing을 해주기 위해, aggregation에서 degree 정보를 활용한다는 것은 결국 전체 그래프 정보(laplacian matrix에 기반한)를 활용한다는 것을 의미하기 때문에 aggregation을 degree가 아닌 것으로 바꾼다는 것은 굉장히 중요한 내용이다. 이 내용은 아래의 그림으로 표현할 수 있는데, 결국 기존 방법은 전체 matrix를 활용해야 하기 때문에 전체 노드 정보를 고려한 파라미터 매트릭스를 학습해야 한다. 이 때문에 Transductive한 학습을 할 수 밖에 없다. 반면 GraphSAGE는 자기 자신의 feature와 인접 노드의 정보만 있다면 Inductive하게 임베딩 벡터를 추출할 수 있게 된다.

Random Walk는 GraphSAGE에서 활용하는 샘플링인데, 기존의 GCN에서는 샘플링 대상을 1-hop adjacency 노드들로 정의했다면 Random Walk는 그래프 연결구조를 통해 랜덤하게 k-hop 까지 시뮬레이션을 통해 이동한 destination 노드들을 샘플링 대상으로 정의한다. 그리고 이렇게 샘플링한 노드들을 degree 정보 없이 sum, mean 등으로 aggregation한다. 만약 여기서 Attention Weight를 aggregation으로 활용한다면 후술할 GAT의 개념이 된다.
2. Pinterest의 PinSAGE가 개선한 내용
PinSAGE에 대한 자세한 설명 및 논문 리뷰는 (링크)를 참고하자.
논문을 한 줄로 요약하자면, PinSAGE는 GCN이 Large-scale 데이터에 적용하기 불리한 이유들을 샘플링 방법으로 개선한 것이라고 볼 수 있다. 아래는 GCN, 그리고 GraphSAGE와 비교해서 볼 만한 PinSAGE의 특징을 요약한 것이다.
1) bi-partite (homogeneous)

Pin과 Board라는 두 개의 Type을 bi-partite 그래프로 표현하였다. 이는 Metapath(Pin - Board - Pin)를 통해 Pin 사이간의 연결정보를 담아내고 결과적으로는 Pin에만 관심이 있는, 즉 Pin에 대해서만 임베딩을 하는 목적을 가지고 있다. Board에는 여러 개의 Pin들을 대표할 수 있는 정보가 있다는 가정이 있는 것이며, 결과적으로는 그래프를 homogeneous한 network로 간주했다는 것이다. 이는 Board 에 대한 정보는 단순히 metapath로만 활용하기 때문에 결과적으로는 Pin 이외 노드 타입의 임베딩 정보는 생성해내지 못한다는 단점(왼손은 거들 뿐...의 느낌?)을 가지고 있지만, 후술할 MultiSAGE에서 이를 해결한다.
2) Neighborhood Sampling With Random Walks
GraphSAGE 알고리즘은 GCN에서 샘플링과 Aggregation을 Large Scale에서도 적용 가능하게 한 것이 핵심이다. PinSAGE는 여기에서 한발 더 나아가서, 이웃을 완전한 uniform random sampling으로 추출하는 것이 아닌, PPR에 기반한 Random Walks로 추출한다(Random Walks로 2-hop 혹은 k-hop 위치에 있는 노드를 샘플링한 뒤, PPR에 기반하여 n개를 고르는 것이다. 여기에서 생성된 edge score는 importance aggregation에도 활용한다). 그리고 이를 통해 Neighborhood Sampling을 구현했다.
3. GAT가 개선한 내용
1) GAT의 개요
GCN에서 GraphSAGE로 넘어가는 것의 핵심은 Aggregate 방식의 변화와 샘플링이었다. PinSAGE는 이 중에서 샘플링 방식에 큰 변화를 줘서 Large-Scale 에서도 GCN을 활용할 수 있도록 한 것이고, GAT는 GCN에서 Aggregate 방식에 큰 변화를 준 것이다. GCN의 Aggregate는 degree를 이용했고 PinSAGE에서의 Aggregate는 PPR(personalize pagerank)을 이용했다. Random Walks의 구조적 특징 상, PPR을 사용하는 것이 훨씬 더 유리하고 성능도 좋은 것으로 나타났지만, PPR이라는 것도 결국 근본적으로는 degree와 같은 의미를 가진다. 즉, 노드의 피쳐정보를 반영하지 않은 pooling score라는 것이다. GAT는 Aggregate를 좀 더 발전시킬 수 있는 방법을 찾던 도중, Attention 메커니즘을 도입하여 이를 해결하고자 한 것이다. 이를 통해 노드의 피쳐정보도 aggregate에 포함시킬 수 있게 된다.
2) Attention 메커니즘
Graph Neural Network에 Attention이 어떻게 적용되는지 이해하기 전에, Attention 메커니즘 자체를 이해해보자. Attention은 <Attention Is All You Need> 라는 유명한 논문을 전후로 모든 ML 분야를 통틀어 가장 빈번하게 사용되는 개념이다. 단어적인 의미는 전체 데이터에서 특정 scope의 데이터에 '집중'한다는 의미이다. 쉬운 이해를 위해 잠시 NLP의 한 가지 예시를 살펴보자.
The animal didn’t cross the street, because it was too tired.
위 문장에서 It이 지칭하는 것을 찾아내려면, It과 관련이 있는 토큰을 찾아내야 한다. Attention 메커니즘은 이러한 문장 단위로 토큰들이 주어질때, 대상 토큰과 나머지 토큰간의 연관성을 찾아내는 데 유용하다. 이를 기반으로 Attention을 다시 정의하면, 문장 내에서 It의 Attention을 구한다는 것은, It과 다른 토큰들과의 연관성을 계산한다는 것이다. 이를 Self-Attention이라고 하는데, 구체적으로 어떤 방식으로 Attention이 수행되는지 알아보자. 우선 3가지의 변수를 정의해야 하는데, 아래와 같다.
- Query: 현재 시점의 token
- Key: attention을 구하고자 하는 대상 token
- Value: attention을 구하고자 하는 대상 token(Key와 동일함)
변수 정의에 따르면 위 문장의 예시에서 Query는 'It'이 된다. Key와 Value는 완전히 같은 벡터를 의미하는데, 만약 Key와 Value가 'animal'을 가리키면 'It', 'animal' 간의 Attention을 구하는 a(it, animal)을 의미한다. 같은 것을 가리키는 벡터를 두 개 사용하는 이유는, 후의 계산과정에서 분리된 2개로 활용하기 위함이다.
그렇다면 이 3개의 벡터는 어떻게 만들어질까? NLP를 기준으로 설명한다면, token 각각의 임베딩 벡터를 input으로 하여 FC layer를 각각 통과시킨 결과값이다. 즉, 3개의 FC layer를 추가적으로 학습해야 한다는 것이다. 그래프 데이터로 이를 생각하면 각 노드마다 가지고 있는 feature가 FC layer의 input이 되고, 3개의 output이 Q, K, V가 된다. 아래의 그림과 같다. (그림에서의 노드 피쳐는 아마도 Projection된 결과를 사용해야 할 것이다)

3) GCN으로의 확장
이를 앞서 살펴본 GraphSAGE, 혹은 PinSAGE로 확장해보자. 위 그림에서는 X노드와 Y노드 간의 Attention Score만을 구했었고, 수식으로 표현하면 다음과 같다. 수식에서의 i, j는 X, Y를 의미한다.
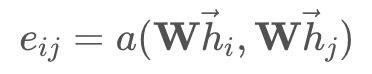
하지만, 이제 Target Nodes를 벡터로 확장할 것이다. 즉, Key와 Value가 되는 Y노드가 벡터 형태로 여러 개가 되는 것이다. 그러면 원래의 Query Attention a(X, Y)가 1 X d_k 가 되었던 것에 반해, n개의 노드로 확장하면 Query Attention a(X, neighbor Nodes)는 n X d_k가 된다. 그리고 이 output 벡터는 각 노드의 중요도 표현을 위해 Normalized 된다.

결국 위 식의 결과(노드 i, j간의 normalized attention score)는 마치 PinSAGE에서의 PPR처럼 edge에 저장되어 importance aggregation에 사용될 수 있게 된다. 더 세부적으로는 ReakyReLU 까지 사용하여 아래와 같이 표현된다.
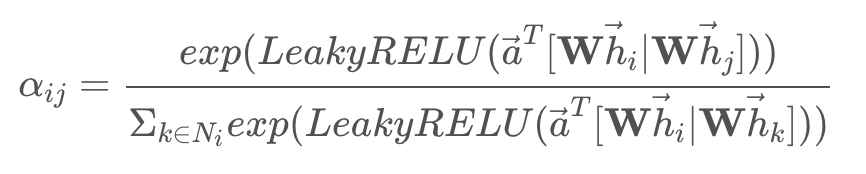
그리하여 최종적으로는 쿼리 노드와 매치되는 각 노드의 Attention Score를 계산할 수 있게 되고, 아래와 같이 이웃의 중요도를 활용하여 Input 데이터를 재정의 할 수 있게 된다. (위에서 살펴본 PinSAGE 코드에서는 PPR score 대신 Attention coefficient로 갈아끼우기만 하면 된다)
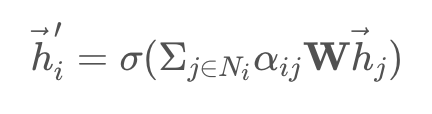
단, GAT 논문에서 사용된 attention은 위에서 설명한 것과 같은 전통적인 dot-product 방법이 아니라, additive attention 방법을 사용한다. (dgl의 GATConv 클래스 역시 이 방법으로 구현되어 있다. 명확한 이유는 나오지 않지만 Graph 구조에서는 additive 방식이 더 효과적인 것으로 보인다)
5. MultiSAGE
1) Algorithm
PinSAGE는 PPR 스코어를 Degree 대신 사용하는데, 이는 결과적으로 성능의 개선은 있었지만 그래프 구조 자체의 정보만을 Edge Score로 사용했다는 한계점을 가지고 있다. 그래서 MultiSAGE에서는 GAT의 Attention 개념을 도입한다. 그리고 Bi-partite 형태로 그래프를 만들고 학습했던 PinSAGE와 달리, Contexualized Multi-Embeddings를 가능케 한다는 것도 차이점이다. 이는 상황에 맞게 임베딩 타입을 다르게 할 수 있다는 것을 의미한다.
우선 PinSAGE의 연장선에서, MultiSAGE에서 개선되어지는 아이디어를 Intuitive하게 이해해보자. Pin-Board-Pin의 Metapath로 연결되어지는 정보에서 Board는 Contextual Node 라고 할 수 있다. 그런데 PinSAGE에서는 Contextual Node 정보는 단순히 Dataset을 생성하는 용도로만 사용되었을 뿐(즉, Board 라는 노드 타입은 Metapath만을 위해 존재하는 노드였다고 할 수 있음), Item과 Item의 유사도를 계산할 때 Contextual Node의 정보는 계산적으로 고려하지 않았다. 아래의 그림에서, Item 3은 Fashion Board를 고려한다면 Item 1,2와 비슷한 느낌일 것이고 Craft Board를 고려한다면 Item 4와 비슷한 아이템일 것이다. PinSAGE에서는 이를 고려하지 않고 단순히 임베딩된 노드 벡터간의 유사도만 고려한다. MultiSAGE의 메인 아이디어는 Contextual Node를 사용하는 것에서부터 시작된다.

이 아이디어를 구현한 것을 이해하기 위해 다시 GAT 내용으로 돌아가보자. GAT에서 Attention Score를 additive attention으로 계산하는 수식에서, Contextual Node 정보를 포함한다는 것은 아래 그림과 같은 상황을 의미한다.

이는 additive attention을 수행할 때, Contextual Node를 Vector representation으로 나타낸 다음(dimension은 node representation의 dimension과 같아야 한다) 가운데 벡터로 삽입하여 concat 요소를 하나 추가하는 것이다. 그리고 다음은 계산된 Edge Attention Score를 활용할 차례다. MultiSAGE에서는 노드의 표현 자체, Raw Input을 다음과 같이 변환한다.
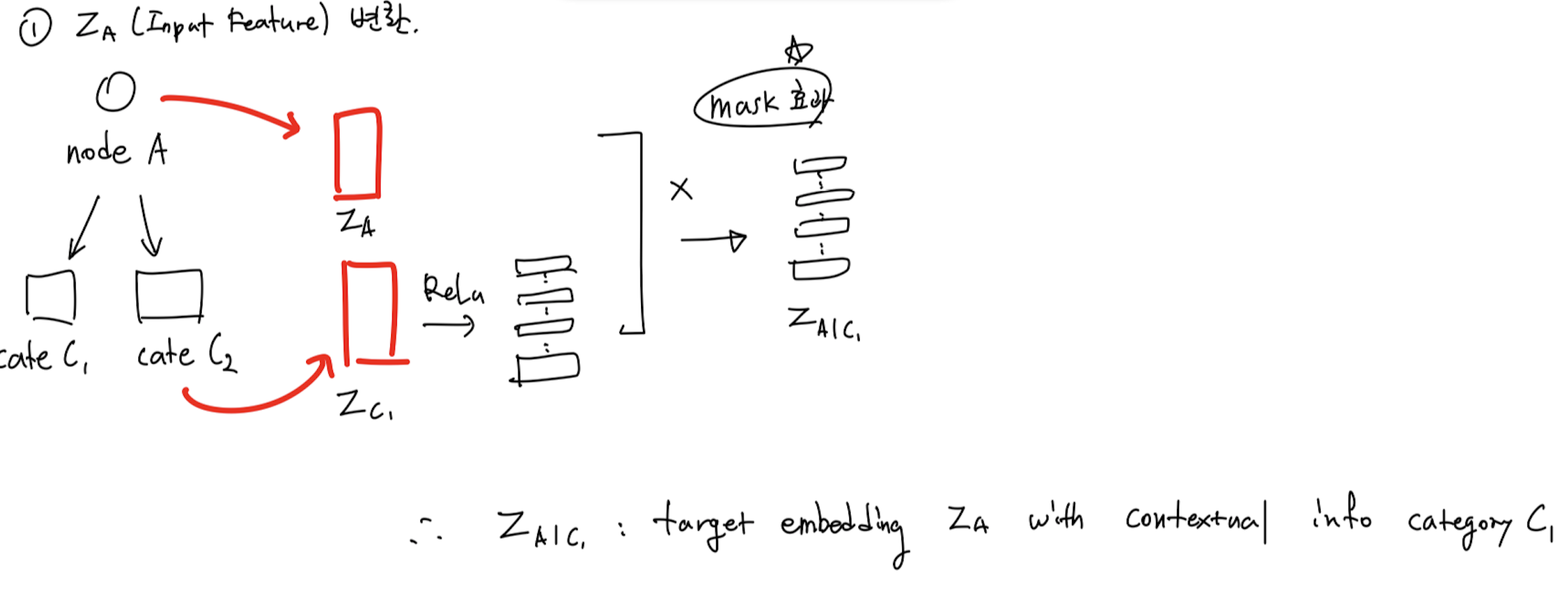
위의 내용을 도식화하고 수식으로 나타낸 것은 아래의 그림과 같다.
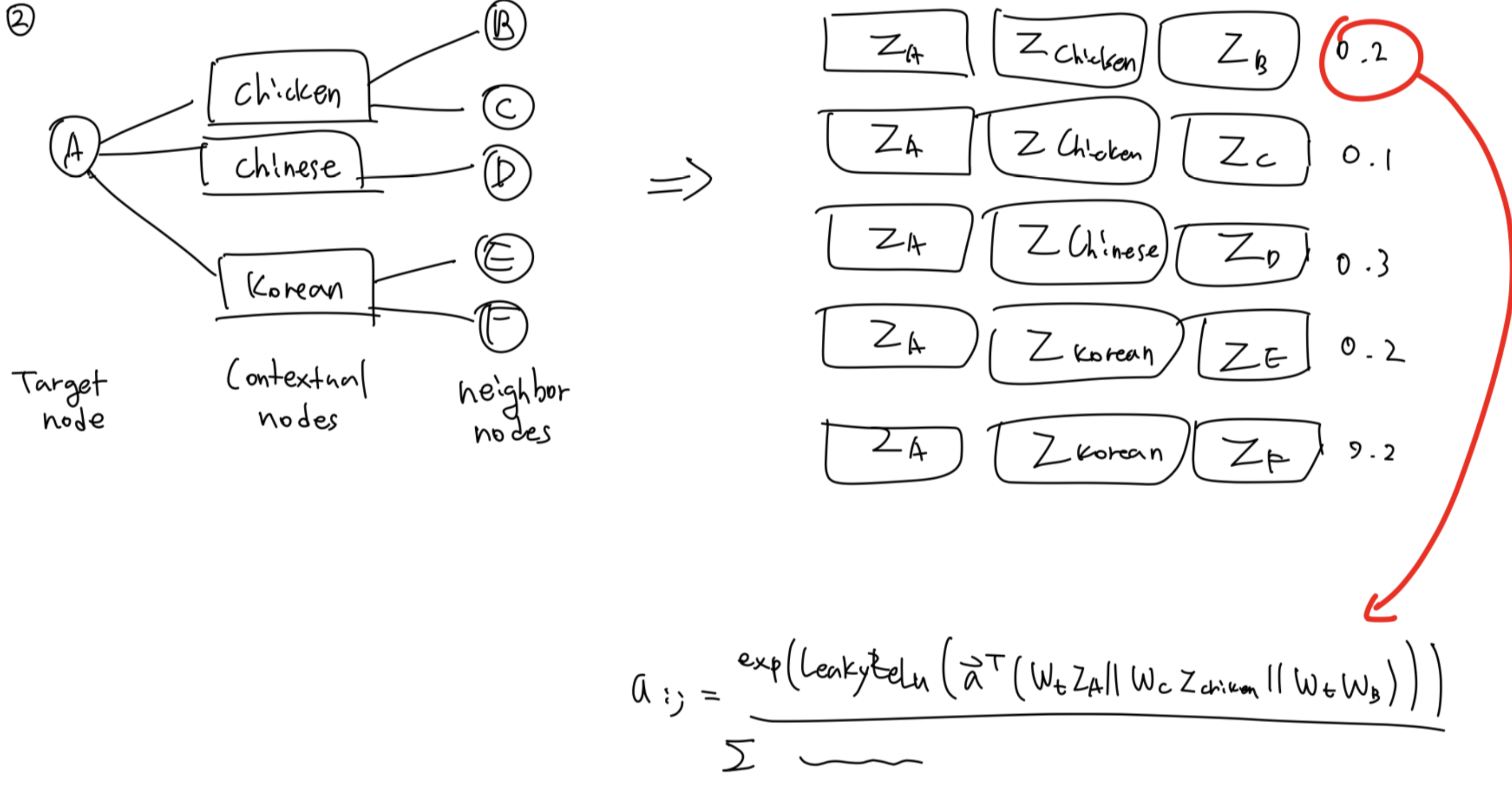
그리고 위의 두 그림의 내용을 종합하면, 기존의 수식 $h_item = Proj(h_item_{t}) + SAGE(h_item_{t-1})$ 이 아래의 그림과 같이 바뀐다는 것을 알 수 있다. Multi-head Attention의 경우, head마다의 결과값을 mean 해주기만 하면 된다.

[논문 링크]
[내용 참고]
- https://yamalab.tistory.com/159?category=948370
- https://yamalab.tistory.com/151?category=948370
- https://yamalab.tistory.com/133?category=948370
- https://docs.dgl.ai/en/latest/guide/minibatch-link.html?highlight=link%20predic
- http://dsba.korea.ac.kr/seminar/?mod=document&uid=1330
[코드 참고]
- https://github.com/dmlc/dgl/tree/master/examples/pytorch/pinsage
- https://docs.dgl.ai/en/latest/tutorials/models/1_gnn/9_gat.html
'Recommender System > 추천 시스템' 카테고리의 다른 글
| [Recommender System] - MovieLens 데이터셋으로 MultiSAGE의 Context Query 구현하기 - 2 (0) | 2021.09.15 |
|---|---|
| [Recommender System] - MovieLens 데이터셋으로 MultiSAGE의 Context Query 구현하기 - 1 (0) | 2021.09.14 |
| [Recommender System] - 결과 정렬에서의 Shuffle 알고리즘 (0) | 2021.04.05 |
| [Recommender System] - 추천시스템과 MAB (Multi-Armed Bandits) (0) | 2021.01.28 |
| [Recommender System] - 임베딩 벡터의 Nearest Neighbor를 찾는 과정 (0) | 2020.12.03 |



