지난 포스팅에 이어, 이번에는 MultiSAGE 알고리즘을 코딩해보자. 모든 실행코드를 보려면 이곳을 참고하자. 그리고 모델 자체에 대한 설명, 혹은 논문에 대한 리뷰는 (링크)를 참고하면 된다.
Context Query in MultiSAGE
MultiSAGE 알고리즘은 GraphSAGE에 GAT(설명 참고)를 적용한 것이라고 할 수 있다. GAT를 한 문장으로 요약하면, Attention 방식으로 그래프 자료구조의 Convolution 연산을 aggregate 하는 것이다. 아래의 그림을 참고하자.
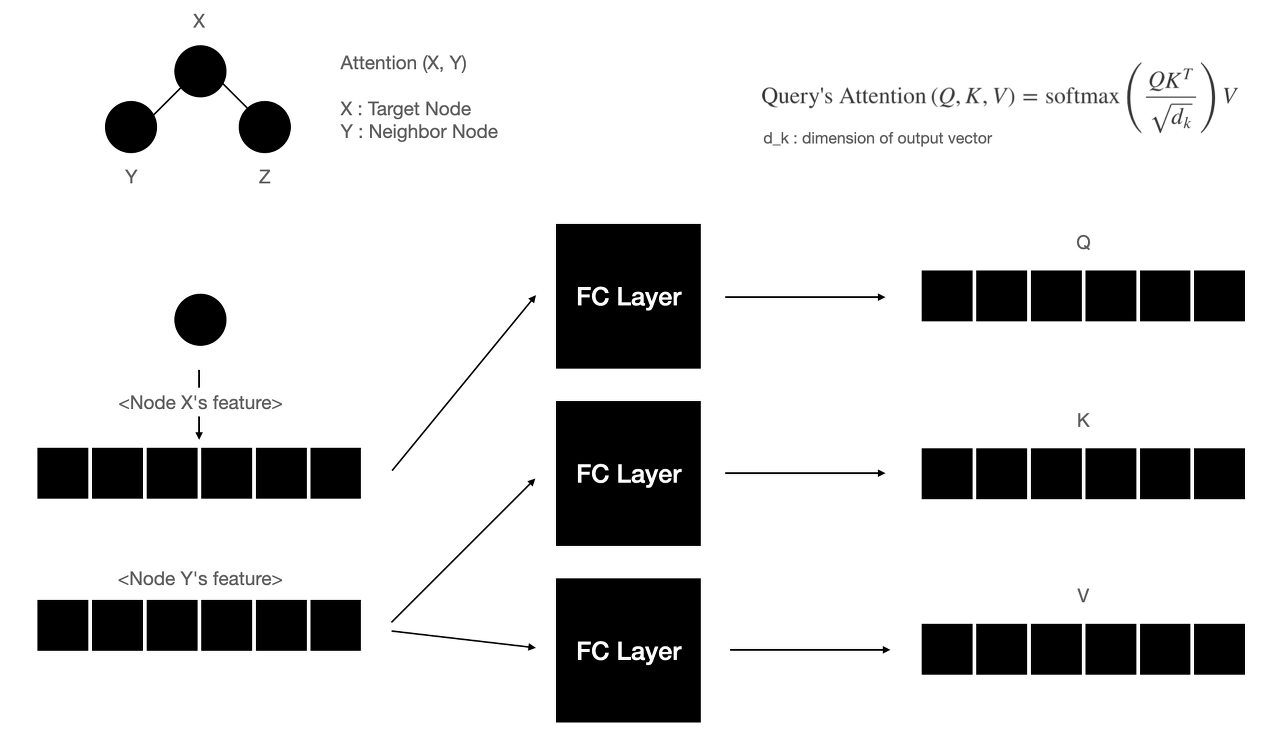
그리고 PinSAGE의 후속 연구인 MultiSAGE의 구조는 PPR 기반의 Random Walk 샘플링으로 Sub-graph를 생성하는 것으로 시작한다. 여기에 Attention 개념을 적용한 뒤, 노드 사이에 있는 Context 라는 Meta-node를 함께 병합하는 구조로 Attention Aggregation을 수행한다. 그래서 GAT와 다른 점의 핵심은 Context Node라는 개념이 들어간다는 것인데, 이 것을 활용하여 Context Query 라는 것을 수행할 수 있다.
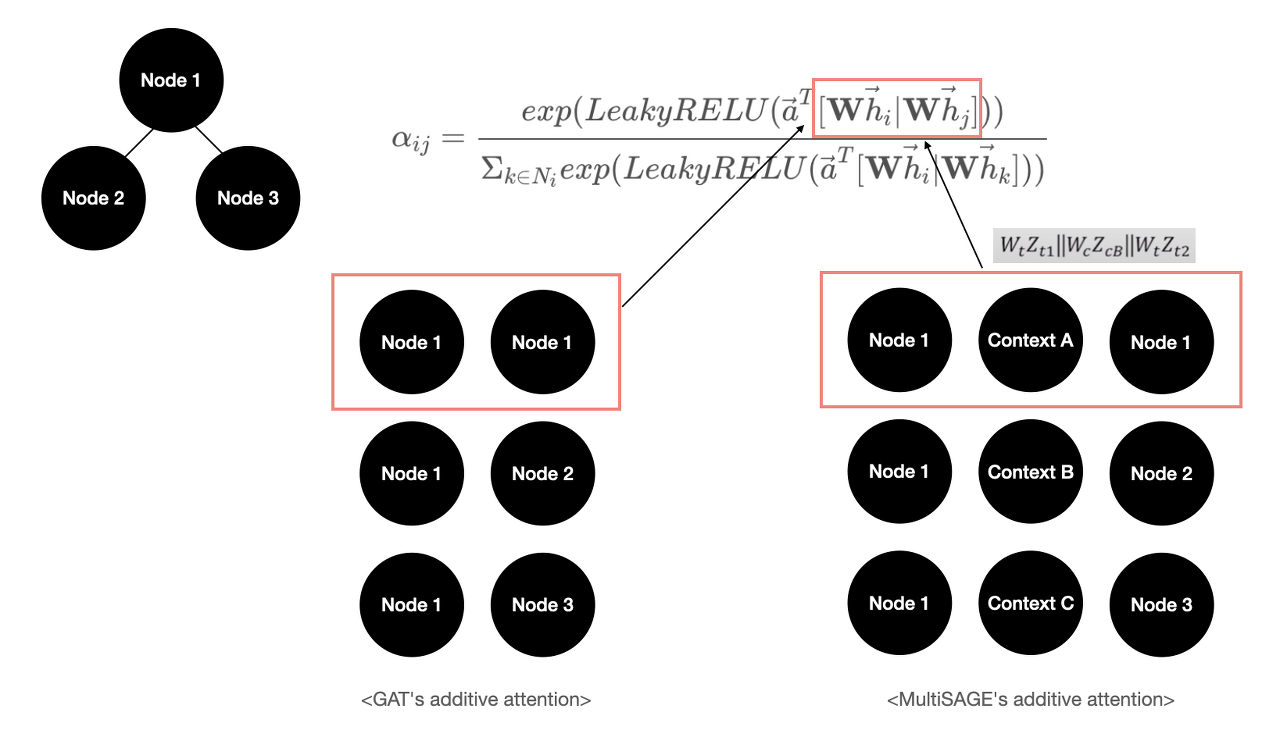
만약 represent(Node 1, Context A) 라는 임베딩 결과를 얻고 싶다면, 위 그림에서 Context A에 해당하는 Node to Node 부분만 Aggregate를 하는 것이다. 코드로 이를 살펴보자.
Graph Building
movies = []
with open(os.path.join(directory, 'movies.dat'), encoding='latin1') as f:
for l in f:
id_, title, genres = l.strip().split('::')
genres_set = set(genres.split('|'))
# extract year
assert re.match(r'.*\([0-9]{4}\)$', title)
year = title[-5:-1]
title = title[:-6].strip()
data = {'movie_id': int(id_), 'title': title, 'year': year, 'genre': genres.split("|")}
for g in genres_set:
data[g] = True
movies.append(data)
movies = pd.DataFrame(movies).astype({'year': 'category'})
ratings = []
with open(os.path.join(directory, 'ratings.dat'), encoding='latin1') as f:
for l in f:
user_id, movie_id, rating, timestamp = [int(_) for _ in l.split('::')]
ratings.append({
'user_id': user_id,
'movie_id': movie_id,
'rating': rating,
'timestamp': timestamp,
})
ratings = pd.DataFrame(ratings)
merged_ratings = pd.merge(ratings, movies, on=['movie_id'])
merged_ratings = merged_ratings[['movie_id', 'rating', 'genre']]
merged_ratings = merged_ratings.explode('genre')
genres = pd.DataFrame(merged_ratings['genre'].unique()).reset_index()
genres.columns = ['genre_id', 'genre']
merged_ratings = pd.merge(merged_ratings, genres, on='genre')
distinct_movies_in_ratings = merged_ratings['movie_id'].unique()
movies = movies[movies['movie_id'].isin(distinct_movies_in_ratings)]
genres = pd.DataFrame(genres).astype({'genre_id': 'category'})
graph_builder = PandasGraphBuilder()
graph_builder.add_entities(genres, 'genre_id', 'genre')
graph_builder.add_entities(movies, 'movie_id', 'movie')
graph_builder.add_binary_relations(merged_ratings, 'genre_id', 'movie_id', 'define')
graph_builder.add_binary_relations(merged_ratings, 'movie_id', 'genre_id', 'define-by')
g = graph_builder.build()
g.nodes['genre'].data['id'] = torch.LongTensor(genres['genre_id'].cat.codes.values)
movies = pd.DataFrame(movies).astype({'year': 'category'})
genre_columns = movies.columns.drop(['movie_id', 'title', 'year', 'genre'])
movies[genre_columns] = movies[genre_columns].fillna(False).astype('bool')
g.nodes['movie'].data['year'] = torch.LongTensor(movies['year'].cat.codes.values)
g.nodes['movie'].data['genre'] = torch.FloatTensor(movies[genre_columns].values)
g.edges['define'].data['rating'] = torch.LongTensor(merged_ratings['rating'].values)
g.edges['define-by'].data['rating'] = torch.LongTensor(merged_ratings['rating'].values)우선 PinSAGE를 구현할 때와 달리, 그래프 자료를 생성하는 것이 조금 다르다. Meta-path를 유저로 활용하는 것이 아닌, 장르로 활용한다. 이 예제에서는 Context Query를 장르로 활용할 것이기 때문이다. 그러면 Q(movie_id, genre)인 쿼리를 날릴 수 있게 된다.
Sampling with Dominant Contexts
from collections import Counter
import numpy as np
from .. import backend as F
from .. import convert
from .. import transform
from .randomwalks import random_walk
from .neighbor import select_topk
from ..base import EID
from .. import utils
class RandomWalkNeighborSampler(object):
def __init__(self, G, num_traversals, termination_prob,
num_random_walks, num_neighbors, metapath=None, weight_column='weights'):
assert G.device == F.cpu(), "Graph must be on CPU."
self.G = G
self.weight_column = weight_column
self.num_random_walks = num_random_walks
self.num_neighbors = num_neighbors
self.num_traversals = num_traversals
if metapath is None:
if len(G.ntypes) > 1 or len(G.etypes) > 1:
raise ValueError('Metapath must be specified if the graph is homogeneous.')
metapath = [G.canonical_etypes[0]]
start_ntype = G.to_canonical_etype(metapath[0])[0]
end_ntype = G.to_canonical_etype(metapath[-1])[-1]
if start_ntype != end_ntype:
raise ValueError('The metapath must start and end at the same node type.')
self.ntype = start_ntype
self.metapath_hops = len(metapath)
self.metapath = metapath
self.full_metapath = metapath * num_traversals
restart_prob = np.zeros(self.metapath_hops * num_traversals)
restart_prob[self.metapath_hops::self.metapath_hops] = termination_prob
self.restart_prob = F.zerocopy_from_numpy(restart_prob)
def _make_context_dict(self, paths):
dom_context_dict = {}
pair_context_dict = {}
# make pair context dict
for path in paths.tolist():
if path[1] != -1:
if (path[0] != -1) and (path[2] != -1):
context = path[1]
pair = (path[0], path[2])
pair_context_dict[pair] = context
if path[3] != -1:
if (path[2] != -1) and (path[4] != -1):
context = path[3]
pair = (path[2], path[4])
pair_context_dict[pair] = context
# make context for single nodes
for item_nodes, ctx_nodes in zip(paths[:, [0, 2, 4]].tolist(), paths[:, [1, 3]].tolist()):
for item in item_nodes:
if item == -1:
continue
for ctx in ctx_nodes:
if ctx == -1:
continue
else:
if item in dom_context_dict:
if ctx in dom_context_dict[item]:
dom_context_dict[item][ctx] += 1
else:
dom_context_dict[item][ctx] = 1
else:
dom_context_dict[item] = {}
dom_context_dict[item][ctx] = 1
# set dorminant context for dst nodes
for k, v in dom_context_dict.items():
dom_context_dict[k] = Counter(v).most_common(1)[0][0]
return (dom_context_dict, pair_context_dict)
# pylint: disable=no-member
def __call__(self, seed_nodes):
seed_nodes = utils.prepare_tensor(self.G, seed_nodes, 'seed_nodes')
seed_nodes = F.repeat(seed_nodes, self.num_random_walks, 0)
paths, hi = random_walk(
self.G, seed_nodes, metapath=self.full_metapath, restart_prob=self.restart_prob)
src = F.reshape(paths[:, self.metapath_hops::self.metapath_hops], (-1,))
dst = F.repeat(paths[:, 0], self.num_traversals, 0)
src_mask = (src != -1)
src = F.boolean_mask(src, src_mask)
dst = F.boolean_mask(dst, src_mask)
context_dicts = self._make_context_dict(paths)
# count the number of visits and pick the K-most frequent neighbors for each node
neighbor_graph = convert.heterograph(
{(self.ntype, '_E', self.ntype): (src, dst)}, # data dict
{self.ntype: self.G.number_of_nodes(self.ntype)} # num node dict
)
neighbor_graph = transform.to_simple(neighbor_graph, return_counts=self.weight_column)
counts = neighbor_graph.edata[self.weight_column]
neighbor_graph = select_topk(neighbor_graph, self.num_neighbors, self.weight_column)
selected_counts = F.gather_row(counts, neighbor_graph.edata[EID])
neighbor_graph.edata[self.weight_column] = selected_counts
return neighbor_graph, context_dicts
class PinSAGESampler(RandomWalkNeighborSampler):
def __init__(self, G, ntype, other_type, num_traversals, termination_prob,
num_random_walks, num_neighbors, weight_column='weights'):
metagraph = G.metagraph()
fw_etype = list(metagraph[ntype][other_type])[0]
bw_etype = list(metagraph[other_type][ntype])[0]
super().__init__(G, num_traversals,
termination_prob, num_random_walks, num_neighbors,
metapath=[fw_etype, bw_etype], weight_column=weight_column)그리고 한 가지 더 수정할 것이 있는데, dgl의 PinSAGESampler 클래스를 수정해야 한다. 이 클래스를 그대로 사용하면, PPR 기반의 RW를 수행하여 Node to Node 정보를 얻게 된다. 하지만 이 Random Walk 도중의 Random Walk Path에서 Context Node ids를 얻어내야 하기 때문에 이 클래스를 수정해준다. 수정 방법은 본인이 원하는 대로 하면 되지만, 필자는 논문의 dominant context를 의미하는 context id를 추출하기 위해 위 코드처럼 수정하였다.
이제 본격적으로 모델 구조를 코딩해보자.
MultiSAGE Class
class MultiSAGEModel(nn.Module):
def __init__(self, full_graph, ntype, ctype, hidden_dims, n_layers, gat_num_heads):
super().__init__()
self.nodeproj = layers.LinearProjector(full_graph, ntype, hidden_dims)
self.contextproj = layers.LinearProjector(full_graph, ctype, hidden_dims)
self.multisage = layers.MultiSAGENet(hidden_dims, n_layers, gat_num_heads)
self.scorer = layers.ItemToItemScorer(full_graph, ntype)
def forward(self, pos_graph, neg_graph, blocks, context_blocks):
h_item = self.get_representation(blocks, context_blocks)
pos_score = self.scorer(pos_graph, h_item)
neg_score = self.scorer(neg_graph, h_item)
return (neg_score - pos_score + 1).clamp(min=0)
def get_representation(self, blocks, context_blocks, context_id=None):
if context_id:
return self.get_context_query(blocks, context_blocks, context_id)
else:
h_item = self.nodeproj(blocks[0].srcdata)
h_item_dst = self.nodeproj(blocks[-1].dstdata)
z_c = self.contextproj(context_blocks[0])
z_c_dst = self.contextproj(context_blocks[-1])
h = h_item_dst + self.multisage(blocks, h_item, (z_c, z_c_dst))
return h
def get_context_query(self, blocks, context_blocks, context_id):
# check sub-graph contains context id
context_id = context_blocks[-1]['_ID'][0].item()
context_index = (context_id == context_blocks[-1]['_ID']).nonzero(as_tuple=True)[0]
if context_index.size()[0] == 0: # if context id not in sub-graph, only random sample context using for repr
return self.get_representation(blocks, context_blocks)
else: # if context id in sub-graph, get MultiSAGE's context query
attn_index = torch.ones(context_blocks[-1]['_ID'].shape[0], dtype=bool)
attn_index[context_index] = False
h_item = self.nodeproj(blocks[0].srcdata)
h_item_dst = self.nodeproj(blocks[-1].dstdata)
z_c = self.contextproj(context_blocks[0])
z_c_dst = self.contextproj(context_blocks[-1])
h = h_item_dst + self.multisage(blocks, h_item, (z_c, z_c_dst), attn_index)
return h전과 달라진 것은 두 가지이다. 첫 번째로 Context 전용 Projection Layer가 하나 더 생겼다는 것이고, 두 번째는 임베딩 벡터를 표현하는 단계에서 Active Attention을 지정해주기 위한 Index를 입력 context id를 기반으로 생성한다는 것이다. 위 코드의 attn_index가 바로 그 부분인데, 이 인덱스가 어떻게 레이어에서 사용되는지 코드로 알아보자.
GAT Layer
class GATLayer(nn.Module):
def __init__(self, input_dims):
super(GATLayer, self).__init__()
self.additive_attn_fc = nn.Linear(3 * input_dims, 1, bias=False)
self.reset_parameters()
def reset_parameters(self):
gain = nn.init.calculate_gain('relu')
nn.init.xavier_normal_(self.additive_attn_fc.weight, gain=gain)
def edge_attention(self, edges):
x = torch.cat([edges.src['z_src'], edges.dst['z_t'], edges.data['z_c']], dim=1)
attention = self.additive_attn_fc(x)
return {'attn': F.leaky_relu(attention)}
def forward(self, block):
block.apply_edges(self.edge_attention)
attention = edge_softmax(block, block.edata['attn'])
return attentionGAT Layer 부분의 구현 코드는 위와 같다. Graph Block에서 additive attention 방법으로 src -> dst 단계의 Attention score를 구한다. 쉽게 이야기하면, 아래의 도식화된 그림을 계산한 것이다. 그리고 이 결과를 Multi-head로도 구현해보자.

Multihead-Attention
class MultiHeadGATLayer(nn.Module):
def __init__(self, input_dims, num_heads, merge='mean'):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(input_dims))
self.merge = merge
def forward(self, block):
head_outs = [attn_head(block) for attn_head in self.heads]
if self.merge == 'mean':
return torch.mean(torch.stack(head_outs), 0)
else: # concatenate
return torch.cat(head_outs, dim=0)Multihead Attention의 개념은 Transformer의 Multihead와 동일하다. 따라서 간단하게 구현하려면 torch.stack으로 결과를 쌓아 mean() 해주면 된다.
MultiSAGE Convolution
class MultiSAGEConv(nn.Module):
def __init__(self, input_dims, hidden_dims, output_dims, gat_num_heads, act=F.relu):
super().__init__()
self.multi_head_gat_layer = MultiHeadGATLayer(input_dims, gat_num_heads)
self.act = act
self.Q = nn.Linear(input_dims, hidden_dims)
self.W = nn.Linear(input_dims + hidden_dims, output_dims)
self.dropout = nn.Dropout(0.5)
self._reset_parameters()
def _reset_parameters(self):
gain = nn.init.calculate_gain('relu')
nn.init.xavier_uniform_(self.Q.weight, gain=gain)
nn.init.xavier_uniform_(self.W.weight, gain=gain)
nn.init.constant_(self.Q.bias, 0)
nn.init.constant_(self.W.bias, 0)
def _transfer_raw_input(self, edges):
return {'z_src_c': torch.mul(edges.src['z_src'], edges.data['z_c']),
'z_t_c': torch.mul(edges.dst['z_t'], edges.data['z_c'])}
def _node_integration(self, edges):
return {'neighbors': edges.data['z_src_c'] * edges.data['a_mean'],
'targets': edges.data['z_t_c'] * edges.data['a_mean']}
def forward(self, block, h, context_node, attn_index=None):
h_src, h_dst = h
with block.local_scope():
# transfer raw input feature
z_src = self.act(self.Q(self.dropout(h_src)))
z_c = self.act(context_node)
block.srcdata['z_src'] = z_src
block.dstdata['z_t'] = h_dst
block.edata['z_c'] = z_c
# getting attention
attention = self.multi_head_gat_layer(block)
if attn_index is not None: # attn_index : index of attention which not in context id
attention[attn_index] = 0
block.edata['a_mean'] = attention
# aggregation
block.apply_edges(self._transfer_raw_input)
block.apply_edges(self._node_integration)
block.update_all(fn.copy_e('neighbors', 'm'), fn.sum('m', 'ns'))
block.update_all(fn.copy_e('targets', 'm'), fn.sum('m', 'ts'))
# normalize for context query
if attn_index is not None:
neighbor = block.dstdata['ns'] / (attention.shape[0] - sum(attn_index).item())
target = block.dstdata['ts'] / (attention.shape[0] - sum(attn_index).item())
else:
neighbor = block.dstdata['ns'] / attention.shape[0]
target = block.dstdata['ts'] / attention.shape[0]
# normalize
z = self.act(self.W(self.dropout(torch.cat([neighbor, target], 1))))
z_norm = z.norm(2, 1, keepdim=True)
z_norm = torch.where(z_norm == 0, torch.tensor(1.).to(z_norm), z_norm)
z = z / z_norm
return z
class MultiSAGENet(nn.Module):
def __init__(self, hidden_dims, n_layers, gat_num_heads):
super().__init__()
self.convs = nn.ModuleList()
for _ in range(n_layers):
self.convs.append(MultiSAGEConv(hidden_dims, hidden_dims, hidden_dims, gat_num_heads))
def forward(self, blocks, h, context_blocks, attn_index=None):
for idx, (layer, block, context_node) in enumerate(zip(self.convs, blocks, context_blocks)):
if (attn_index is not None) and (idx == 1):
h_dst = h[:block.number_of_nodes('DST/' + block.ntypes[0])]
h = layer(block, (h, h_dst), context_node, attn_index)
else:
h_dst = h[:block.number_of_nodes('DST/' + block.ntypes[0])]
h = layer(block, (h, h_dst), context_node)
return hAttention index를 mask처럼 활용하는 Context Query는 마지막 convolution 레이어에서만 수행된다. 즉 "1-depth to target"인 상황에서만 context query를 질의한다는 것이다. 그래서 MultiSAGENet 에서는 -1 인덱스에 해당하는 부분에서만 attention index를 파라미터로 넘겨준다.
핵심적인 Convolution 코드는 위의 MultiSAGEConv 클래스에서 수행된다. Contextual Node를 Vector representation으로 나타낸 다음(dimension은 node representation의 dimension과 같아야 한다) 가운데 벡터로 삽입하여 concat 요소를 하나 추가하는 과정을 포함한다. 그리고 attention을 계산한 뒤, context node가 맞는 attention index가 아니면 값을 모두 zero padding 처리한다. 그 이후 message passing 코드로 임베딩 벡터 표현을 차례로 계산하면 된다.
핵심적인 코드들은 위와 같고, 전체 코드를 실행해보고 싶다면 위의 깃헙 링크에 방문하길 바란다. 그러면 마지막으로, 이 Context Query가 제대로 구현된 것인지 확인해보도록 하자.
Result
# Comedy Query
index_ids = tree.query(context_batch.numpy()[0], 10)[1]
movie_ids = [index_id_to_movie_id[idx] for idx in index_ids]
for mid in movie_ids:
print(movies[movies['movie_id']==mid]['title'].values)위 코드는 코메디 장르로 Context Query를 질의한 것이다. 결과 확인에 대한 코드 역시, 주피터 노트북의 형태로 업로드 해두었으니 궁금한 사람은 링크에서 확인해보도록 하고, 아래의 결과를 보자.
질의 대상이 되는 영화는 'Grumpier Old Men' 이라는 영화인데, 영화를 보지 않아서 잘은 모르겠지만 로맨스/코메디 장르가 짬뽕된 미국식 영화라고 한다. 임베딩 벡터를 기준으로 Similar Movie를 찾아보면, 비슷한 영화들이 잘 나오는 것을 알 수 있다.
['Perez Family, The']
['Sabrina']
['Pie in the Sky']
['Englishman Who Went Up a Hill, But Came Down a Mountain, The']
['Forget Paris']
['Clueless']
['Rendezvous in Paris (Rendez-vous de Paris, Les)']
['While You Were Sleeping']
["Pyromaniac's Love Story, A"]
['Vampire in Brooklyn']
이번에는 로맨스 장르로 Context Query를 질의해 본 결과, 아래와 같이 나왔다.
['French Kiss']
['French Twist (Gazon maudit)']
['Grumpier Old Men']
['Incredibly True Adventure of Two Girls in Love, The']
["Pyromaniac's Love Story, A"]
['Vampire in Brooklyn']
['While You Were Sleeping']
['Rendezvous in Paris (Rendez-vous de Paris, Les)']
['Forget Paris']
['Englishman Who Went Up a Hill, But Came Down a Mountain, The']
순위가 조금 바뀌고, '로맨스' 스러운 영화들이 더 잘 나온다는 것을 확인할 수 있다. 아마도 성공적으로 Context Query가 적용된 것 같다.
'Recommender System > 추천 시스템' 카테고리의 다른 글
| [Recommender System] - Sequential Recommendation (feat. BERT4REC) (0) | 2022.07.06 |
|---|---|
| [Recommender System] - MovieLens 데이터셋으로 MultiSAGE의 Context Query 구현하기 - 1 (0) | 2021.09.14 |
| [Recommender System] - GCN과 MultiSAGE 알고리즘 (0) | 2021.07.26 |
| [Recommender System] - 결과 정렬에서의 Shuffle 알고리즘 (0) | 2021.04.05 |
| [Recommender System] - 추천시스템과 MAB (Multi-Armed Bandits) (0) | 2021.01.28 |



