-
[Recommender System] - Sequential Recommendation (feat. BERT4REC)Recommender System/추천 시스템 2022. 7. 6. 18:39
최근에는 GNN 관련 모델 구현, 그리고 시스템적으로 개발할 것들이 많아서 새로운 모델이나 알고리즘을 접할 일이 없었다. 퇴근 후에는 투자 공부에만 집중하고 있어서 ML쪽으로는 조금 소강 상태... ㅋㅋ 여튼 그러던 와중에 오랜만에 새로운 모델을 리서치할 일이 있기도 하고, Session-based Recommender System이 마침 궁금하던 찰나이기도 해서 BERT4REC 모델을 시간을 내서 조금 들여다보고 있다.
BERT4REC은 알리바바에서 발표한 논문(BERT4REC : Sequential Recommendation wtih Bidirectional Encoder Representations from Transformer)에 소개된 추천 모델을 의미한다. 이름에서 유추할 수 있듯이, 보통 NLP 분야에서 사용되던 BERT를 추천시스템에 적용한 것이다. NLP 쪽은 큰 관심이 없어서 Transformer 모델과 Attention 구조를 이해하는 정도까지만 알고 있는데, 제목만 보고는 BERT가 sequential prediction이 되던가? 하는 생각이 들었다. Task를 next prediction으로 하는 BERT Task가 있는 것은 알고 있지만, 그쪽 방면에서는 성능이 다른 모델에 비해 떨어진다고 알고 있었기 때문. 뭐 결론만 얘기하자면, 오히려 추천시스템처럼 세션과 행동이 명확한 데이터에서 BERT가 next prediction 으로 잘 동작한다고 한다.
본 포스팅에서는 Transformer와 Banila BERT 모델, 그리고 BERT4REC 논문의 내용 일부를 살펴보면서 간만에 추천시스템과 관련된 이야기를 하려고 한다.
1. BERT (Bidirectional Encoder Representations from Transformers)
1) Transformer
BERT는 Bidirectional Encoder와 Directional Decoder를 가진 Transformer 구조에서 Bidirectional 구조에만 집중한 모델이다. 주로 NLP 분야에서 번역과 같은 Task에 널리 활용된다.

일반적인 Transformer 구조는 Positional Encoding된 입력 벡터들을 Attention으로 한번에 계산한다. 이는 Token들의 한 문장 안에서의 맥락을 동시에 고려하기 위함이다. 만약 Love, You 라는 단어가 각각 따로 있다고 한다면, 무엇을 Love 하는지, You는 무엇을 지칭하는지가 애매해지지만 함께 존재한다면 그 의미와 대상이 명확해지는 상황을 떠올려보자. 이 상황에서 맥락을 고려하기 위해 함께 계산하는 원리가 바로 Attention이다. 이 때 Encoder Attention은 Bidirectional, Decoder Attention은 Directional의 메커니즘을 가지게 된다.
그리고 Bidirectional Encoding 이라는 것은, 아래의 그림과 같은 구조를 가졌으며, 역할을 수행하는 모델이라고 할 수 있다.

2) Position Embedding
Bidirection 구조에서 가장 중요한 것은 역시 Input Embedding이라고 할 수 있다. 그래서 Input Embedding을 잘 만들어내는 것이 이 모델의 성능을 좌우하는 요소라고 할 수 있겠다. 논문에서 언급하는 방식은 3가지로, Token Embedding, Segment Embedding, Position Embedding이 있다.

이미지 출처 : https://wikidocs.net/31379 그 중에서도 중요한 것은 Position Embedding인데, 이는 단어의 위치정보를 활용하기 위함이다. BERT의 인코더는 Self-Attention 메커니즘을 활용하는데, 이 경우에는 입력값의 순서가 모두 무시되기 때문이다. 그래서 sin 함수, cos 함수를 활용하여 positional한 정보를 만들어내는데, 아래의 이미지처럼 토큰마다 임베딩 차원을 고려하여 positional encoding 벡터를 더한다.
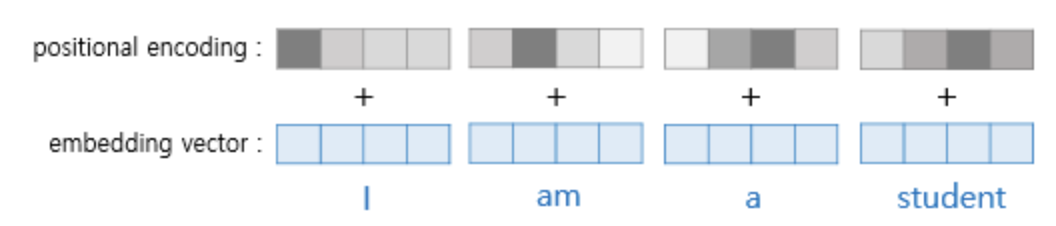
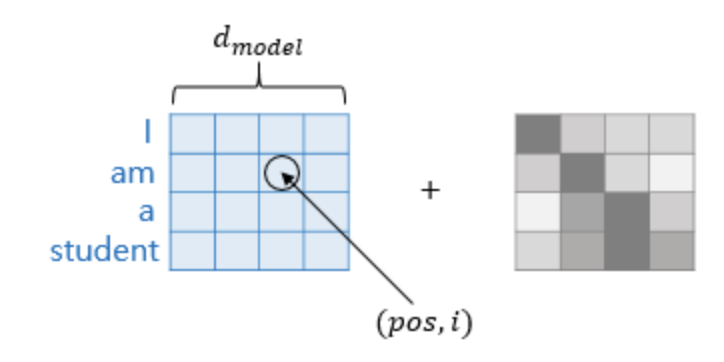
잘 설명된 이미지가 있어서 가져왔는데, 이를 행렬 단위로 보면 아래의 이미지와 같다. 트랜스포머는 위치정보를 가진 값을 만들기 위해서 이와 같은 두 개의 함수를 동시에 사용하는데, 여기에서 pos와 i는 그림과 같은 위치정보를 표현하는 것이다. 왜 이런 방식으로 임베딩 벡터를 표현하는지는 직관적으로는 사실 잘 모르겠지만, 여튼 그렇다고 한다.
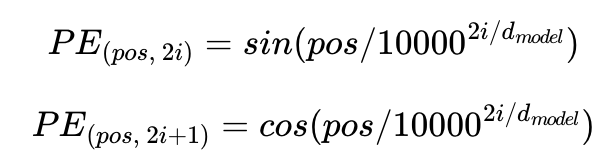
이미지 출처 : https://wikidocs.net/31379 3) Self-Attention
다음으로 BERT 모델의 인코더 구조에 대해 조금 더 자세히 알아보자. 트랜스포머의 인코더 구조만 따왔기 때문에, BERT의 임베딩 구조는 Self-Attention 으로 계산된다. 즉, 아래의 그림과 같은 구조로 연산이 이루어짐.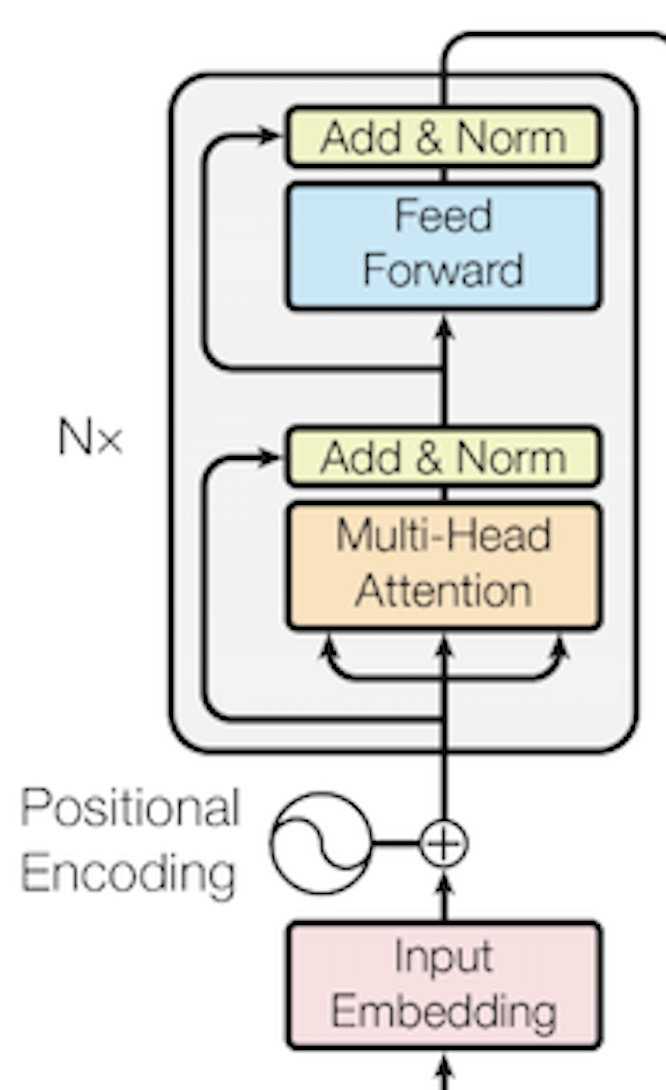
어텐션 함수는 주어진 쿼리(Q)에 대해서 모든 키(K)와의 유사도를 각각 구한 뒤, 이 유사도를 가중치로 하여 키와 매핑되어있는 각각의 값(V)을 곱해주는 것이다. 그리고 이를 모두 가중합하여 반환하는 결과이다. 하지만 셀프 어텐션 함수는 Q, K, V가 모두 동일한 주체를 의미한다(동일하다는 말의 의미는 아래를 보면 이해할 수 있다). 그리고 모델 내에서 Self-Attention은 입력 임베딩 벡터를 한번 더 변환한 뒤에 다음 연산을 수행한다. 입력 벡터 d가 있다고 할 때, 아래처럼 새로운 행렬 3개를 다시 생성해내는 과정이다.
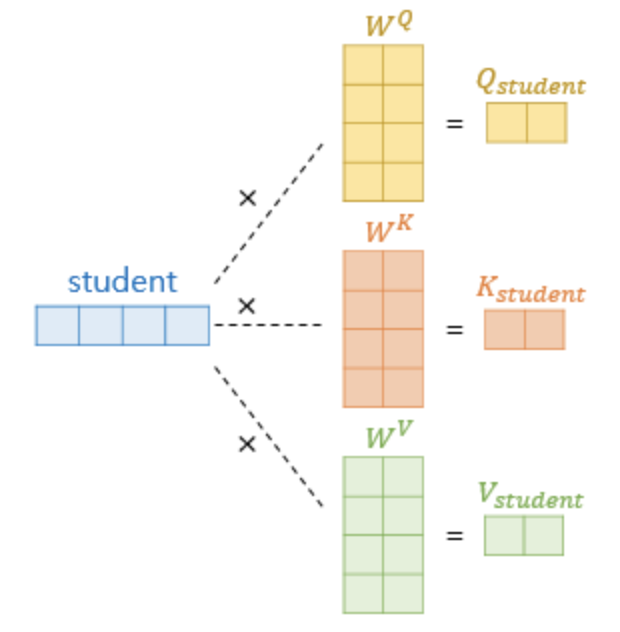
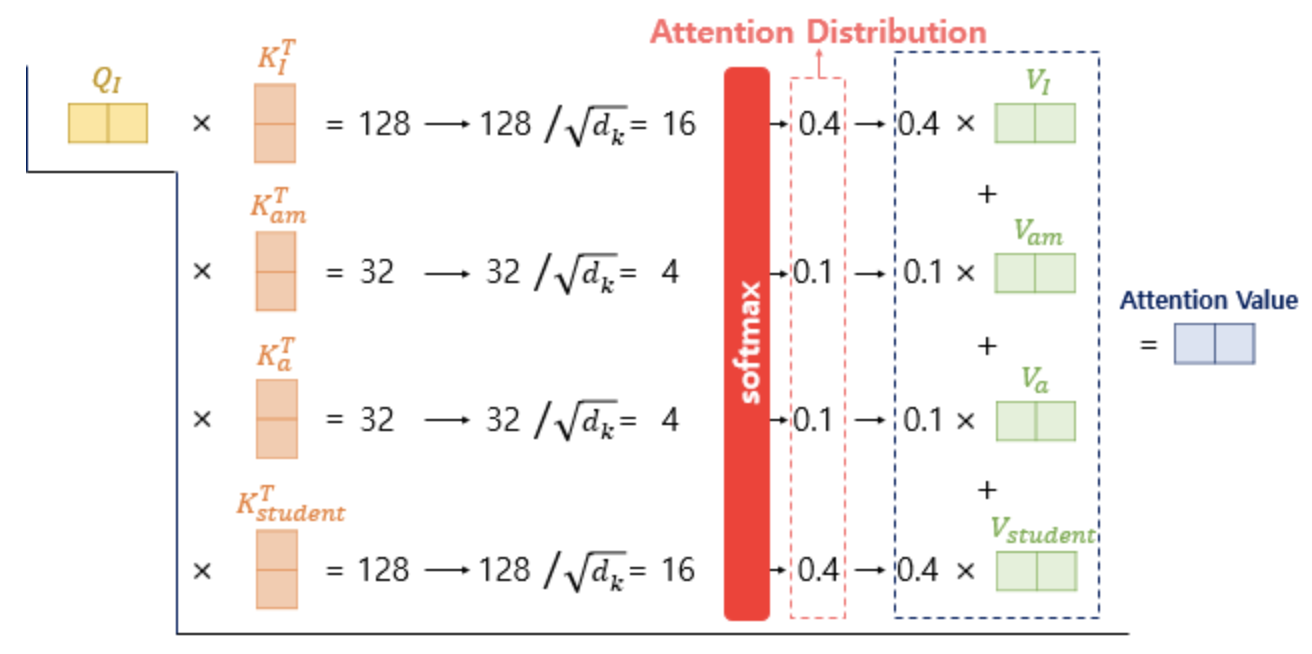
이미지 출처 : https://wikidocs.net/31379 Transformer 논문에서는 원래 단어의 차원이 512이고, Q,K,V 벡터의 차원은 64이다. 이는 multi-head가 8개이기 때문인데, single attention의 결과를 나중에 가서 Concatenation 하기 때문. 그리고 어텐션 스코어는 아래와 같이 계산된다([16,4,4,16]). 위에서 말한, 주어진 쿼리(Q)에 대해서 모든 키(K)와의 유사도를 내적곱으로 구하는 것은 단순 내적곱을 활용한 스코어링 방법이고, 그림에서는 여기에 나누기항까지 추가한 Scaled dot-product로 스코어를 계산한다. 그리고 이 결과에 softmax 함수를 적용하여 한번 더 Normalization 해준 뒤 V를 곱하여 가중합 결과를 "I" 라는 쿼리의 어텐션 스코어값으로 표현한다. 이는 "I" ,"AM", "A", "STUDENT" 라는 모든 단어와의 관계성 및 중요도를 고려하여 자신("I")을 표현한 것이라고 추상화하여 이해할 수 있다.
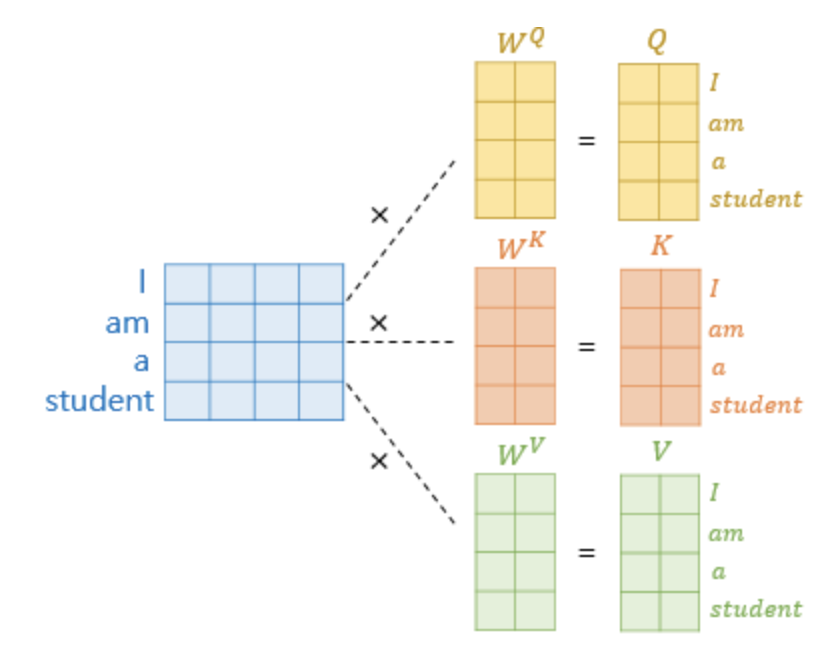
이미지 출처 : https://wikidocs.net/31379 그리고 이를 모든 Q에 대해 한번에 계산하기 위해, 행렬의 성질을 이용한다. 아래의 그림과 수식대로 계산하면, 하나의 셀프 어텐션에 대한 어텐션 Value Matrix가 생성된다. 그리고 이를 Multi-head에 적용하면 (논문에서는 8개) 8개의 결과가 나오는데, 8개를 단순히 concatenate하면 어텐션의 입력 벡터와 차원을 맞출 수가 있다.
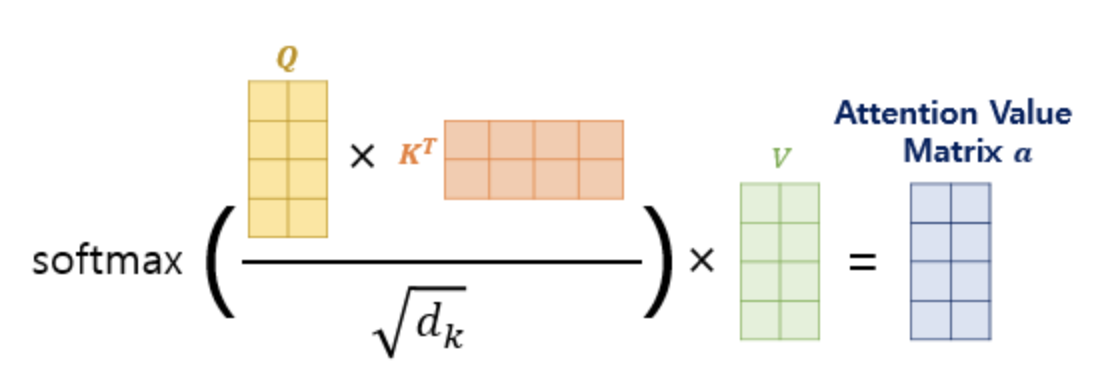
이미지 출처 : https://wikidocs.net/31379 multi-head 방식으로 어텐션을 여러 개 계산한 뒤 합치는 이유는 앙상블의 원리를 떠올려보거나, 혹은 Multi-modal Task의 Expert를 떠올려보면 된다. 그리고 후에 살펴볼 BERT4REC 논문의 실험 결과에서도 head별 attention matrix와 layer별 attention matrix를 시각화하여 살펴본 결과가 있는데, 실제로 각각 다른 Expert 처럼 기능한다고 한다.
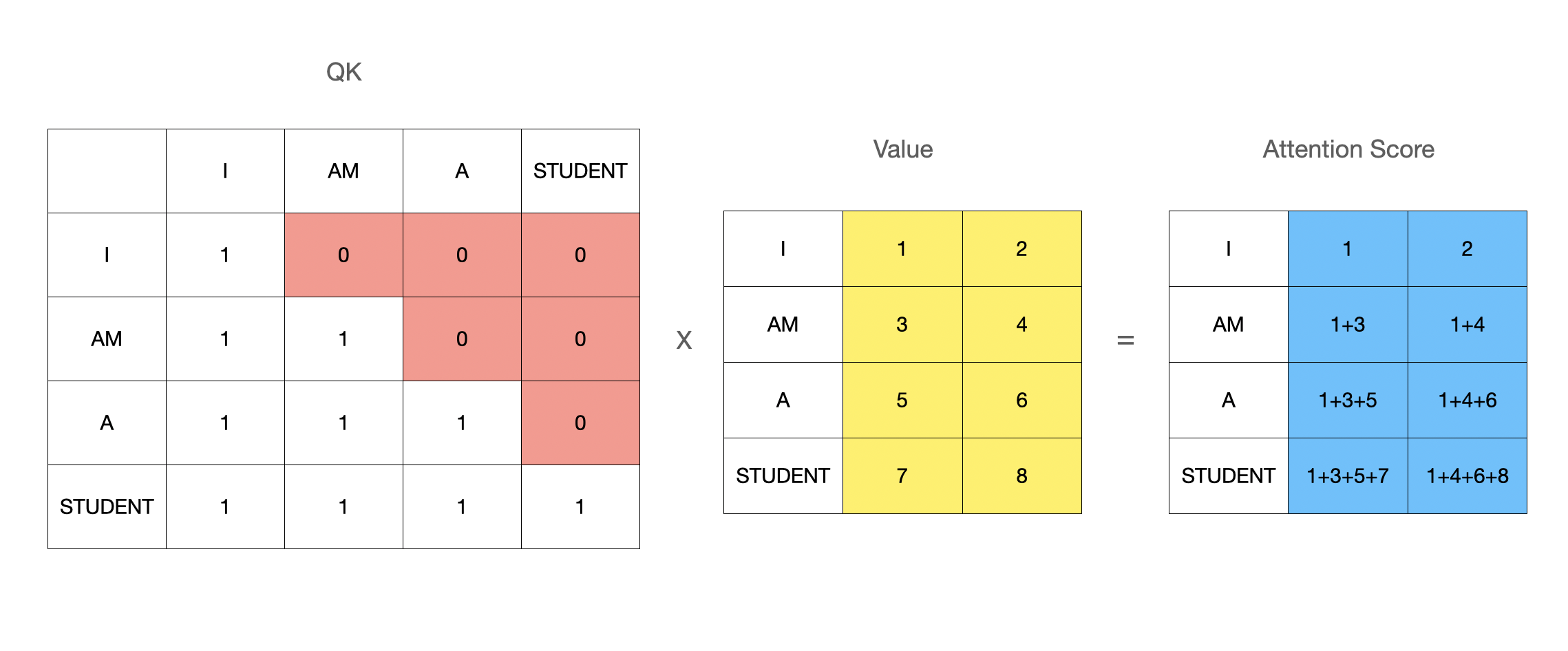
Attention 계산 시, 입력 토큰의 Sequential한 요소를 고려하기 위한 마스킹 기법 그리고 BERT에서는 생략되는 내용이 한 가지 있는데, 바로 sequential masking 기법이다. Transformer의 decoder의 경우 sequential한 정보를 고려하기 위하여 위의 그림에 표시된 것(0으로 마스킹) 처럼, Self-Attention을 계산할 때 마스킹 기법을 활용하는 게 좋다고 한다. 첫 번째 Token을 탐색할 때는 세션 내에 첫 번째 Token에 대한 기록밖에 없고, 두 번째 Token을 탐색할 때는 세션 내에 2개의 Token이 있기 때문이다. BERT는 인코딩 부분만을 활용하고 있기도 하고, BERT4REC에서는 특히, 활용하는 prediction task가 의외로 이런 기법이 소용이 없어서(?) 이 부분은 적용하지 않았다고 한다.
그 외에도 Multi-head Self Attention의 과정에서 몇 가지 내용들이 있는데, 요약하자면 패딩(Padding)에 대한 내용, FN(Feed-Forward Neural Network)에 대한 내용, 그리고 Residual Connection(Add)에 대한 내용이 있다. 패딩값의 활용은 간단히 말하면 V 행렬에 패딩값(극미 음수)을 적용하는 게 끝이다. 이를 통해 Softmax 계산 시에 0에 수렴하는 값이 되기 때문. 그리고 FN은 같은 층의 인코더 안에서는 다른 단어들마다 모두 같은 값으로 사용되지만 다른 층의 인코더마다는 다르다. 즉 12-layer의 인코더 층을 가지고 있다면 서로 다른 FN은 12개라는 것이다. 마지막으로 Residual Connection은 인코더의 입력 벡터값과 Multi-head 어텐션의 결과값을 더하는 것(Add)이다. 그리고 이 모든 과정을 거친 후에 Layer Normalization을 거친다. 이 요소들을 그림으로 표현하면 아래와 같다.
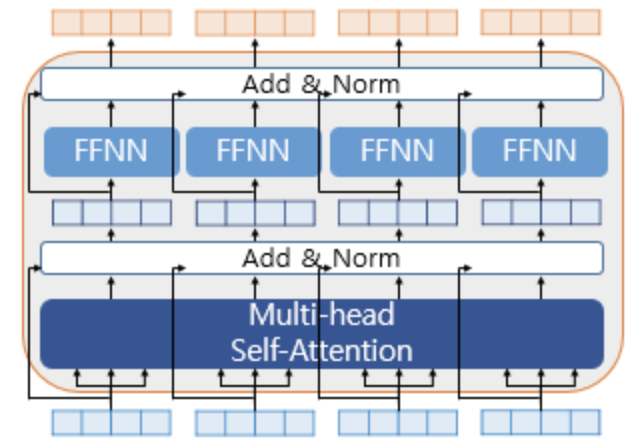
이미지 출처 : https://wikidocs.net/31379 4) Pre-Training
BERT 모델은 unsupervised 데이터에 사용하기 좋은 모델이다. 그래서 사전 훈련을 어떻게 시키느냐에 따라 이를 활용한 supervised task의 성능 역시 결정된다고 할 수 있다. BERT는 사전 훈련을 위해서 입력 Token 중, 15%정도를 랜덤으로 마스킹한다. 그리고 모델에게 이 마스크를 예측하도록 한다. 중간마다 단어들에 구멍을 뚫어놓고, 구멍에 들어갈 단어들을 예측하게 하는 것이다. 즉, 아래의 그림처럼 마스크를 예측하는 모델을 학습시키는 메커니즘을 가지고 있다.
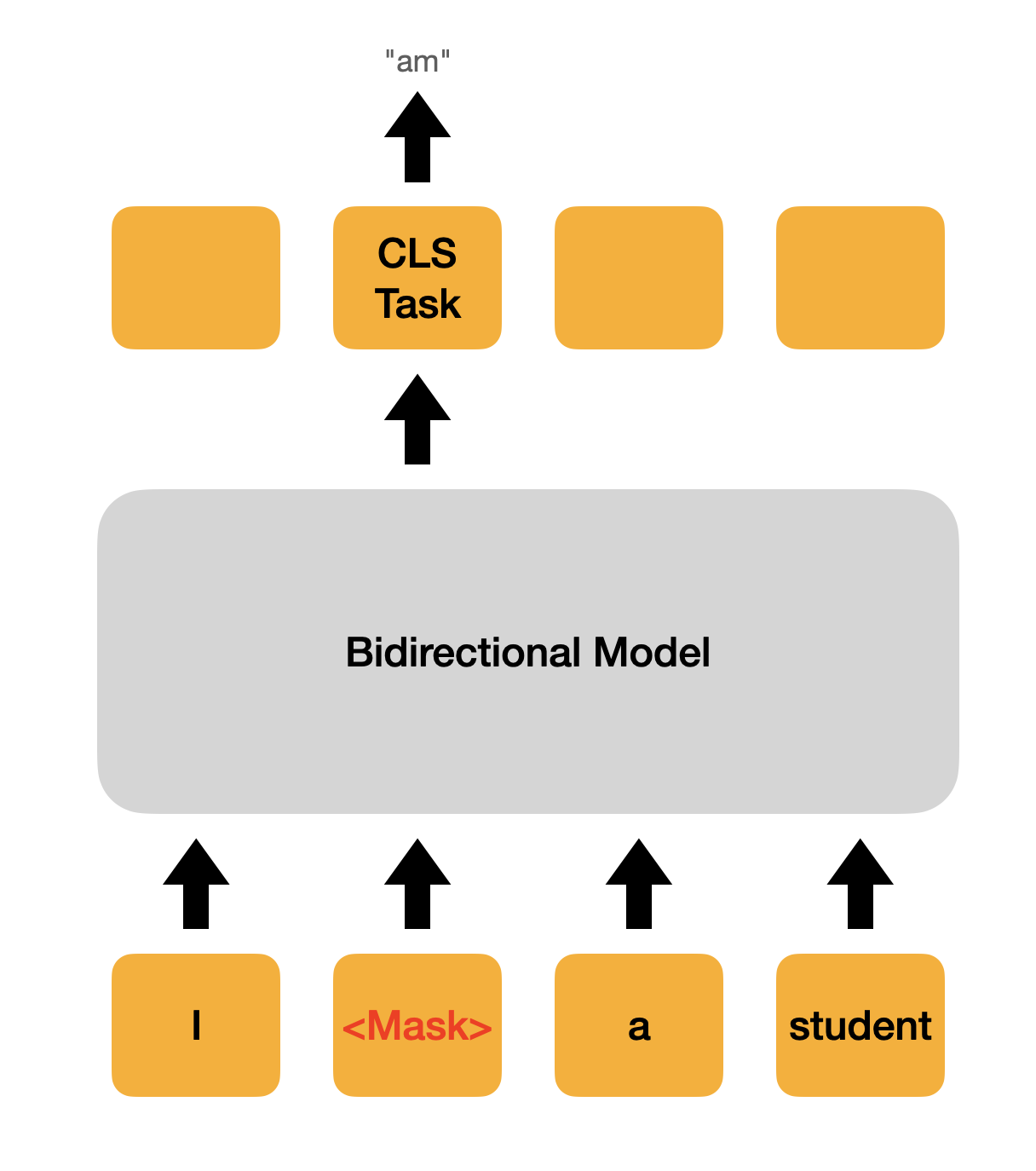
2. BERT4REC : Sequential Recommendation wtih Bidirectional Encoder Representations from Transformer
1) Abstract
Recommender System에서는 BERT를 어떻게 활용할까? BERT4REC 이라는 논문에 그 답이 있다. BERT4REC은 알리바바에서 발표한 추천 기술 관련 논문으로, E-commerce 도메인의 sequential한 특징에 기반한 모델이라고 할 수 있다. 가장 강력하면서 보편적인 추천 모델이라고 할 수 있는 협업필터링, 혹은 GNN과 같은 알고리즘은 유저가 선호하는 아이템을 정의하는 데는 매우 좋은 성능을 낼 수 있으나, 한 가지 도메인의 특징을 간과한 것이 있다. 바로 Sequential한 Discovery이다. 그래서 BERT의 특징을 활용하여 sequential prediction을 수행하는 것이다.일반적으로 생각하기에 BERT는 Sequential한 prediction 문제를 풀기 위한 최적의 선택지는 아닐 것 같지만, 다른 모델을 생각해보면 딱히 좋은 대안이 있는 것도 아닌 것 같다. GRU나 LSTM과 같은 시퀀스 모델은 순차적 계산을 해야 하기 때문에 연산 속도도 문제가 있고, Long-term에 대한 정보를 반영하기도 어렵다. 그래서 Attention 메커니즘을 차용한 Bidirectional한 연산을 사용하는 BERT가 조금 더 추천시스템에 적합하다고 할 수 있지 않을까.
2) Architecture
BERT4REC은 이 그림 한장으로 모델의 거의 모든 것을 설명할 수 있다.
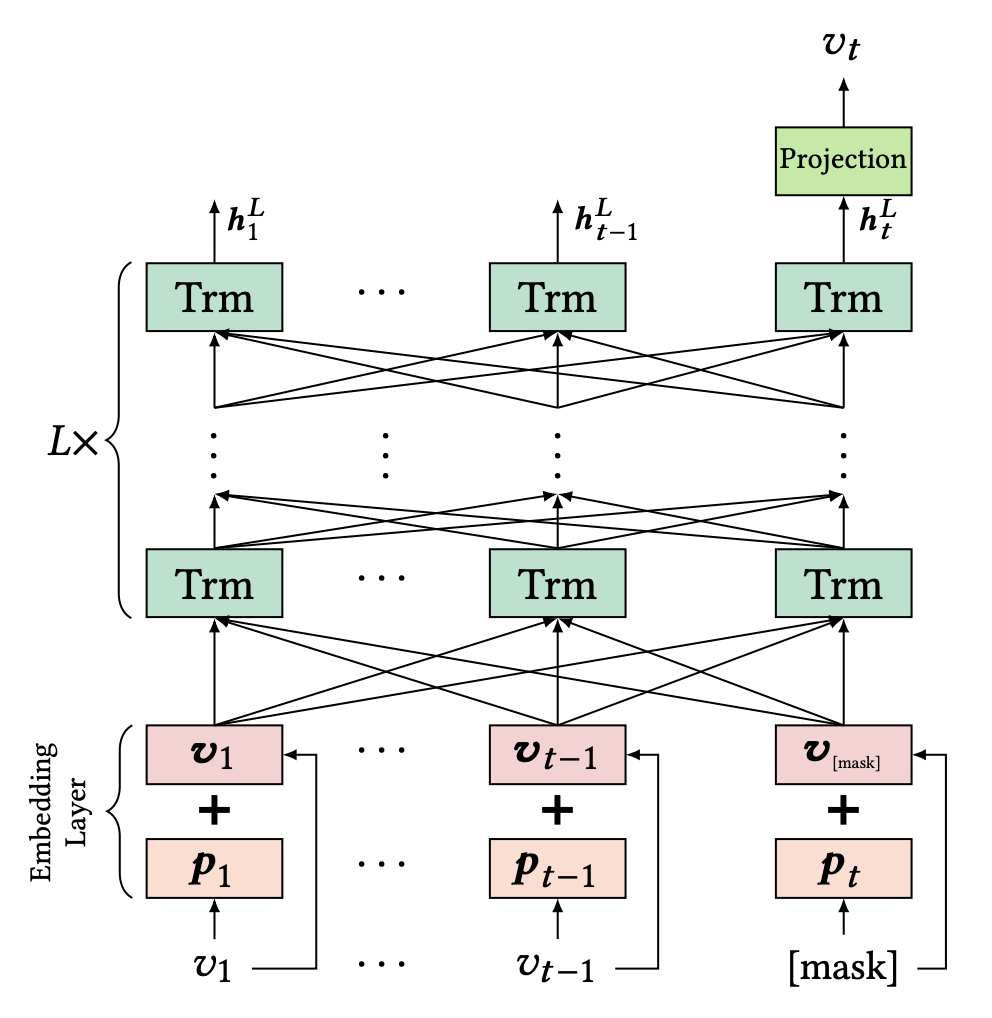
p는 유저의 세션 내에서 특정 시점에 어떤 아이템을 구매할지에 대한 probability를 모델링한 것이다. Trm은 Transformer의 Encoder 레이어를 축약한 것이고, 동일 층의 Trm 레이어의 output을 모아서 다음 레이어에서 동일한 Trm 연산을 수행하는 구조이다. 일반적인 BERT 레이어와 다르지 않으며, 아래의 수식을 따라 구하면 된다.
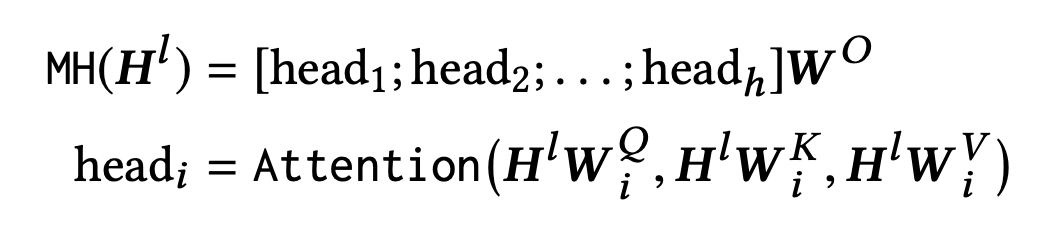
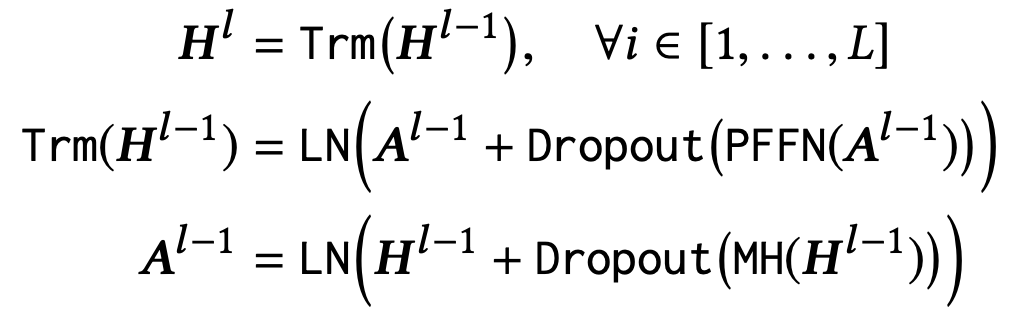
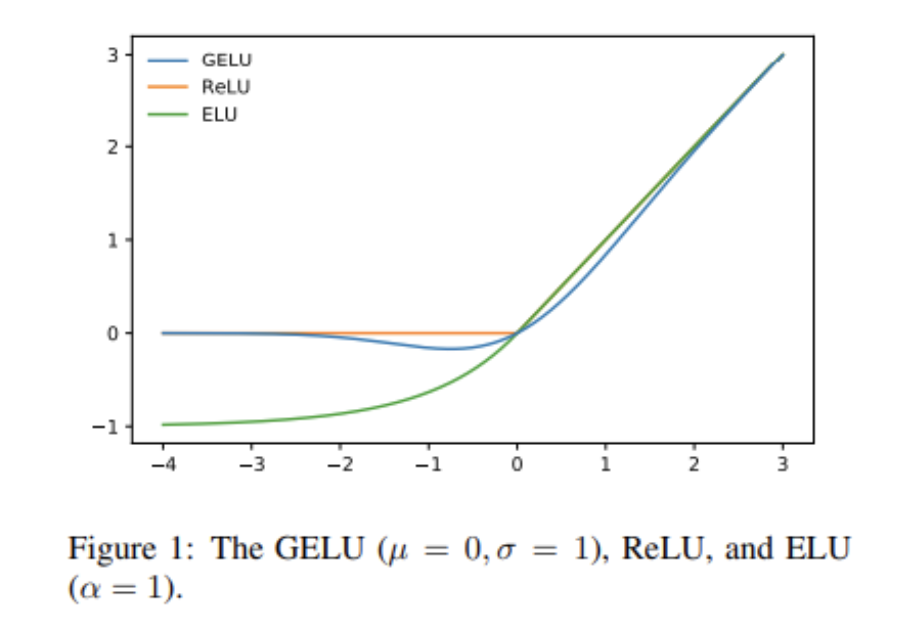
그림에서 v_t만 표현되어 있는 것은, BERT4REC이 next item을 예측하는 Task를 가지고 있기 때문이다. t개의 아이템이 있는 세션이라고 할 때, v1부터 v_(t-1)까지의 아이템의 임베딩 벡터를 입력값으로 사용하고 t 시점에서는 Mask를 한다. 그리고 최종 Output projection 벡터에서 이를 실제 아이템을 정답으로 두고 학습하는 방식이다. 큰 의미가 있어보이지는 않지만, activation function이 relu가 아니가 gelu 라는 것을 사용했다고 한다. (수렴에 이르는 학습 속도의 개선 측면에서 의미가 있다고 함)
일반적으로 predicting the next item을 수행하는 경우, RNN 베이스 모델은 input sequence가 shift 되기 때문에 순서를 반영해야 하는 Training 시에 효율적이지 못하다. 이를테면, ([v1], v2), ([v1, v2], v3)...을 계속 만들어내야 하는 모양새이다. 하지만 BERT의 Masked Language Model의 아이디어를 이용하면 이를 조금 더 효율적으로 학습할 수 있게 된다. 즉, 아래의 그림처럼 Masked 된 부분을 predict 하는 방식으로 Pre-train을 시키는 것이다. 그리고 이를 도메인적 특성에 녹여내기 위해, 마지막 item만 mask를 하여 학습시키는 과정까지 거치면 BERT4REC Train 과정을 모두 거치게 되는 것이다.
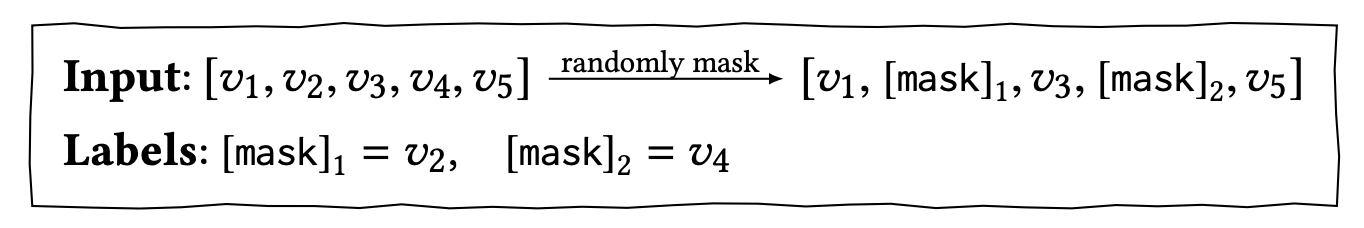
3) Results
사실 논문의 실험 결과는 별로 중요하게 생각하지 않는 편이다. 실험에서 사용하는 실제 데이터와는 너무 거리가 있는 데이터이기도 하고, 모든 논문에서 자기가 SOTA 라고 주장하는게 일관된 결론이기 때문이다. 여튼, 그것과는 별개로 실험 결과에 대한 분석이 굉장히 흥미로운데, 위에서 언급한 것처럼 Attention Matrix 레이어에 대한 시각화 부분이 바로 그것이다.

위에서 말했던 Positional Embedding을 생각해보면 이해하기 쉬운데, 그림이 시사하는 바는 Layer가 1일 때 보다 Layer가 2일 때 Position에 대한 정보를 더 강하게 반영한다는 것이다. 왼쪽 값에서 오른쪽 값으로 갈수록 score가 진해지기 때문에 t번째 item에 대한 attention을 계산할 때 최근 item에 가까울수록 더 높은 가중치로 계산된다는 것을 알 수 있기 때문. 그리고 head 1과 head 2를 비교한 (a)와 (b)를 보면, t시점 아이템에 대한 다양한 특성을 헤드마다 다르게 학습하는 것을 알 수 있다. 이는 Multi-modal 모델에서 Expert가 다른 Convolution Filter를 만들어내는 것과 유사한 효과인 듯 하다.
그리고 논문에 언급된 또 하나의 요소는 데이터셋마다 유저의 Session의 길이 차이가 심하다는 것인데, 이를 최적화하는 것이 사실상 모델의 핵심인것 같다. 내 생각에 BERT4REC은 장점이 명확한 만큼 모델의 한계 또한 명확한데, 논문에서의 실험 결과는 모델을 실제 추천시스템에 적용하기에는 다소 어렵다는 이야기를 돌려서 하는 것 같다. 실제 추천시스템에서는 유저의 세션 데이터를 실시간으로 모으기도 어려울 뿐더러, BERT라는 모델의 복잡성을 고려했을 때, inference 단계에서도 가성비를 뽑기는 힘들다. 물론 이런 문제들을 모두 극복했을 때는 아주 좋은 성능을 낼 수 있다는 말이기도 하다. 검색을 해보니 현재 국내에서 규모가 큰 아주 추천시스템에 BERT4REC이 적용된 사례는 아직 없는 것 같은데, 그런 이유에서인 듯 하다. 또한 대부분의 추천시스템이 Session-based Recommendation보다는 Candidate Generation 혹은 Ranking System이 더 중요하기 때문일 것이다. 하지만 논문의 저자가 알리바바의 리서치 엔지니어인 만큼, 분명 잘 정리해서 사용한다면 실제 시스템에서도 유용하게 쓸 수 있을 것으로 보인다. (중국 애들이 이상하게 이런건 거짓말 잘 안한다;;)
참고자료
- https://wikidocs.net/31379
- https://wikidocs.net/115055
- https://www.youtube.com/watch?v=30SvdoA6ApE
- https://www.youtube.com/watch?v=4pYHEzwTa78
- https://www.youtube.com/watch?v=d2IaWtBbJjg
- https://www.youtube.com/watch?v=PKYVHGrSO2U
'Recommender System > 추천 시스템' 카테고리의 다른 글
[Recommender System] - MovieLens 데이터셋으로 MultiSAGE의 Context Query 구현하기 - 2 (0) 2021.09.15 [Recommender System] - MovieLens 데이터셋으로 MultiSAGE의 Context Query 구현하기 - 1 (0) 2021.09.14 [Recommender System] - GCN과 MultiSAGE 알고리즘 (0) 2021.07.26 [Recommender System] - 결과 정렬에서의 Shuffle 알고리즘 (0) 2021.04.05 [Recommender System] - 추천시스템과 MAB (Multi-Armed Bandits) (0) 2021.01.28 댓글